ChatGPT的爆火,多模态大模型GPT-4的发布以及全面植入微软Office全家桶,百度也推出了同样具备多模态能力的“文心一言”(ERNIE),甚至李开复、英特尔首席架构师Raja Koduri也准备下场角逐—今年以来,以此为代表的内容生成式AI(AIGC,AI Generated Content)应用快速破圈,掀起基于大语言模型(LLM)的生产力革新浪潮。
就像一个正在飞速进化的新物种,全民AIGC是否将推动新一轮生产力变革的新时代到来?
ChatGPT令AI从everywhere到everyone
1956年夏,麦卡锡(John McCarthy)、明斯基(Marvin Minsky)、罗切斯特(Nathaniel Rochester)和香农(Claude Shannon)等科学家首次提出“人工智能(Artificial Intelligence,简称AI)”这一概念,标志着人工智能学科的诞生。在经历了数次寒冬与泡沫之后,坎坷的人工智能探索道路才终于随着ChatGPT的走红而实现了从“不能用、不好用”到“可以用”的技术突破,并进一步走向实用化。

“事实上,在这一轮ChatGPT浪潮之前,AI技术已经是随处可见(everywhere)。比如边缘AI计算已被广泛应用于包括消费电子、工业和汽车设备在内的众多细分市场,包括语音交互、人脸识别、图像优化、安防监控、自动驾驶等等。”芯原执行副总裁、IP事业部总经理戴伟进对集微网评论说,“随着AI技术的不断演进,它从以往处理特定任务,发展到今天像ChatGPT一样与人互动,回答问题,这种具备思考和学习能力的工具能够使每个人(everyone)的休闲娱乐或工作从中受益。”
ChatGPT的开发逻辑,是基于Transformer架构的语言模型,通过学习大量预先标注的文本数据(包括网络新闻、书籍、学术文献等),生成与人类语言相似的文本。通过数据中心、计算机硬件设备等进行模型的运行、文本数据的计算处理,以服务器、存储器、网络接口输入输出设备等硬件为基础。
虽说ChatGPT可以初步用于提高生产力,但是基于GPT-3.5的ChatGPT仍存在缺点和瓶颈。 “无论你问什么,它总会给你一个答案,不管是否准确,可能就是一些‘正确的废话’。”戴伟进表示,“包括ChatGPT在内的AIGC应用仍需技术迭代演进,首先是训练的数据量,其次就是算法模型的参数量。”比如最新发布的多模态GPT-4模型,其参数量更大,模型迭代时间更长,可识别图像,也能够给出更准确的结果,具有更广泛的常识和解决问题的能力。
ChatGPT实质是对话式AI的应用,IDC数据显示,对话式AI市场规模在2022年达到54.6亿元人民币,其市场渗透率相对已经饱和。ChatGPT引发的浪潮促使主流厂商在其对话式AI应用中引入大模型,将带动对话AI相关市场新一轮增长。此外,在搜索、营销场景中,ChatGPT类型的应用则可能衍生出全新的产品形态。
随着OpenAI开放了GPT-4的API,戴伟进预测它将成为老少咸宜的、提高生产力的工具,而智慧出行领域将是最先落地的应用场景之一。
现阶段,作为市场主流的交互方式,智能语音是智能座舱的标配功能,然而当前车载语音系统的交互程度普遍较弱,用户体验一般,大多时候沦为“鸡肋”。“ChatGPT将极大地推动自然语言处理(NLP)AI的商业化应用,为汽车中语音交互系统带来新的可能。”他强调,“人人能用”很酷,这样一项非常实用的技术将会吸引更多人来开发需求,挖掘商业价值,使AI从研究项目真正成为可商业化大规模投资的产业,进而形成活跃的生态圈。
ChatGPT引发AI算力告急
观察GPT系列从1到3的发展过程,都是基于Transformer架构,并且探出一条路,就是可以通过海量数据,超强算力,让NLP产生质的变化。既然ChatGPT等AIGC应用的“智力”增长,建立在对海量数据的训练上,算法、数据、算力是生成式AI不可或缺的三大关键,算力做为硬件基础决定AI“智力”的上限。OpenAI发布的AI模型算力报告中指出,与2012年的模型相比,2020年提出的模型需要600万倍的计算能力;预计从2023到2028年,AI所需算力将再增加100万倍。IDC也预测,中国智能算力需求规模,到2026年将进入每秒十万亿亿次浮点计算(ZFLOPS)级别,达到1,271.4EFLOPS,从2021到2026年,年复合增长率将达52.3%。
戴伟进表示,AI运算可以简单归纳为云端运算、边缘运算和移动边缘计算三个场景,对相关算力芯片的性能、功耗和延时等关键指标有着不同的需求。ChatGPT背后的算力支撑正是基于分布式运算的云端运算集群。
据TrendForce估算,处理1800亿个参数的GPT-3.5大模型,需要的GPU数量高达2万枚,未来GPT大模型商业化所需的GPU数量甚至超过3万枚。而根据英伟达的公告,微软Azure上部署了数万枚A100/H100高性能芯片。这是第一个采用英伟达高端GPU构建的大规模AI算力集群。
“以云端运算、数据中心为支撑的AI运算,需要的是GPU、GPGPU、以及TPU/NPU/VPU ASIC加速芯片等为代表的大算力芯片。”戴伟进指出,过去数据中心曾经用CPU,性能增长越来越难以跟上AI算力需求,而并行运算的GPU更适合用于高并发的深度学习任务。去掉或减弱GPU的图形显示能力的GPGPU,则将其余部分全部投入通用计算,实现处理人工智能、专业计算等加速应用。再辅以TPU/NPU等加速模块,这三大类芯片构成了AI算力的基石。
另外,戴伟进还指出,由于AI运算需要对海量数据进行处理,数据存取能力也在很大程度上限制了AI运算速度,存储性能跟不上的话,会导致GPU在那里等待,无事可做,空转浪费算力,因此通用存储和缓存技术等数据存取架构的创新也越来越急迫。
目前,ChatGPT已经令英伟达成为这场算力革命的最大赢家。部分业内人士认为,如果英伟达在其人工智能GPU业务中看到了机会,它可能会优先供应人工智能GPU,而不是游戏GPU。ChatGPT以及随后涌现的诸多AIGC应用必然会让供应已然十分紧缺的高性能GPU再次告急。
如何打造中国版“ChatGPT”
ChatGPT火爆全网之时,“背水一战”的百度也推出了中国版“ChatGPT”文心一言。李彦宏直言“大模型训练堪称暴力美学,需要有大算力、大数据和大模型,每一次训练任务都耗资巨大。”尽管文心一言收获了众多围观者褒贬不一的反馈,但不可否认其对算力基础设施的需求必将驱动AI芯片市场井喷。
戴伟进指出,对于中国AIGC市场发展而言,数据、算力、算法是驱动力也是瓶颈所在。随着高端计算芯片在国内的发展一再受限,AI芯片领域的国产替代势在必行。
要打造中国版“ChatGPT”,我们还需要突破哪些瓶颈?
戴伟进认为,首先中文语料的训练量要比用英文训练的ChatGPT大得多,训练时间也还远远不够,需要进一步积累。比如文心一言中文语料占比约75-85%,与GPT3.5对比,量级是后者10倍以上。“这需要时间。”
其次是算力挑战。虽然高性能GPU成为主流的AI算力芯片,但实际上在AI运算中,需要的核心模块更多是并行运算单元和神经网络加速单元,因此GPGPU被视为AI时代的算力核心。“对于AI芯片厂商来说,需要真正明白自己需要的是哪部分的功能,虽然国内在并行运算单元性能上与英伟达还有一定差距,但是通过NPU单元,以及数据存取方面的创新,有效解决芯片性能瓶颈问题,何乐而不为呢?”
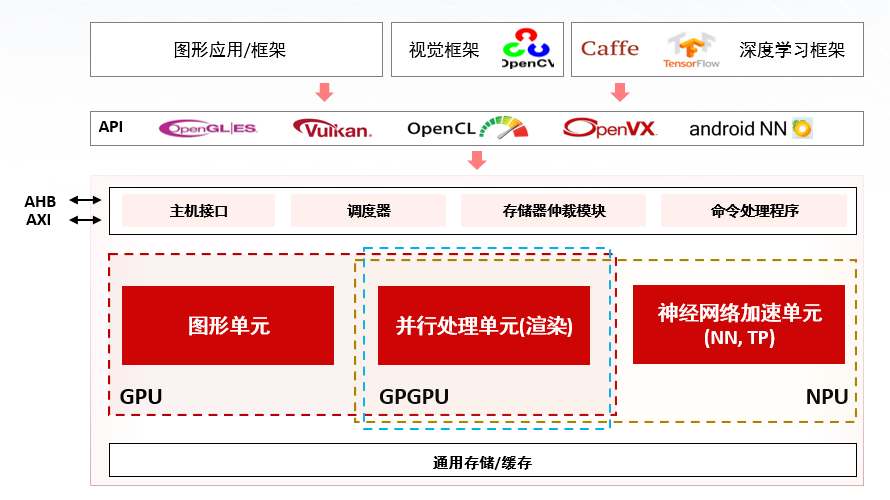
芯原Vivante GPU/GPGPU/NPU架构
“作为中国排名第一,全球排名第七的半导体IP提供商,芯原已拥有六类自主处理器IP。针对AI芯片,芯原基于超过20年Vivante GPU的研发经验,推出了GPU、GPGPU、NPU等AI芯片所需的系列IP组合,可提供从边缘AI运算低功耗嵌入式设备,到云端AI运算高性能服务器,再到智能驾驶等应用所需的计算能力,满足广泛的人工智能计算需求。”他表示,“如今芯原的NPU IP已被全球60余家客户用于其110余款人工智能芯片中,这些芯片应用于物联网、可穿戴设备、安防监控、汽车电子、服务器、智慧电视、智慧家居、智能手机、平板电脑、智慧医疗等众多场景。未来,公司将在AIoT、可穿戴设备、汽车电子、数据中心这四个领域专注半导体IP的研发与平台化升级。”
他解释,针对客户不同的应用场景需求,芯原的处理器IP可通过对图像处理单元、并行计算单元和神经网络加速单元的差异化“配比”来实现不同芯片尺寸和功耗预算的定制化设计,并提供完整的软件栈和SDK,支持主流的深度学习框架,包含Tensorflow、PyTorch、ONNX、TVM、IREE等,支持OpenCL和OpenVX等编程API。
据悉,目前芯原多家车载领域的客户,已经将基于芯原IP打造的GPGPU、NPU用于训练Transformer模型。“随着基于大模型的AI迅速展现强大的商业价值,芯原的相关IP也越来越受欢迎。部分客户开始在此基础上开发第二代芯片产品,也有更多客户将芯原的NPU IP部署到他们的GPU中,以提高运算性能。”戴伟进透露,“除了智能驾驶领域,数据中心和服务器领域也是芯原持续关注的重点研发方向,结合自身技术优势努力挖掘新的市场机会。”
最后,戴伟进还重点强调了数据存取技术领域的创新。“以往行业关注的重点大多在于处理器的创新,存储领域已经20年没有出现重大的技术突破了,行业龙头和初创企业都在努力解决,国内在这个领域还是有机会的。”
结语
尽管越来越多“大神”加入到AIGC的大潮中,但这种大语言模型离真正掌握做类比推理的能力还有一定的距离。而各路“ChatGPT”的破圈成长还需不断以模型的优化,训练规模的提速以及算力资源的扩充来支撑。
无论是为了实现技术的安全可控,还是为了应对AI算力性能和数量均“告急”的瓶颈,都驱动着国内AI芯片厂商另辟蹊径。芯原的GPGPU+NPU的DSA异构设计思想,为广大国产算力芯片设计者提供了一个从“能用”到“好用”的多元算力解决方案。
(校对/王梓凌)