(1)字符型变量按照拼音首字母排序
在做AE一类的table时,经常会有要求,需要我们先按照例次降序排序,如果例次相同按照SOC拼音首字母排序,例次降序排好理解,但是怎样才能实现对字符型变量按照拼音排序呢?用一个例子来让大家理解:
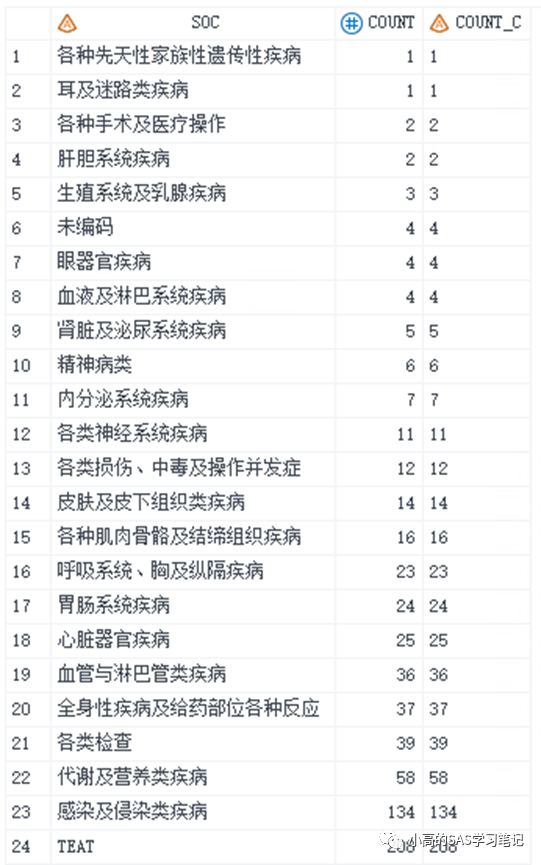
/ 测试数据集 /
data test;
set order;
count_c=put(count,best.);
run;
/ 结果如下: /
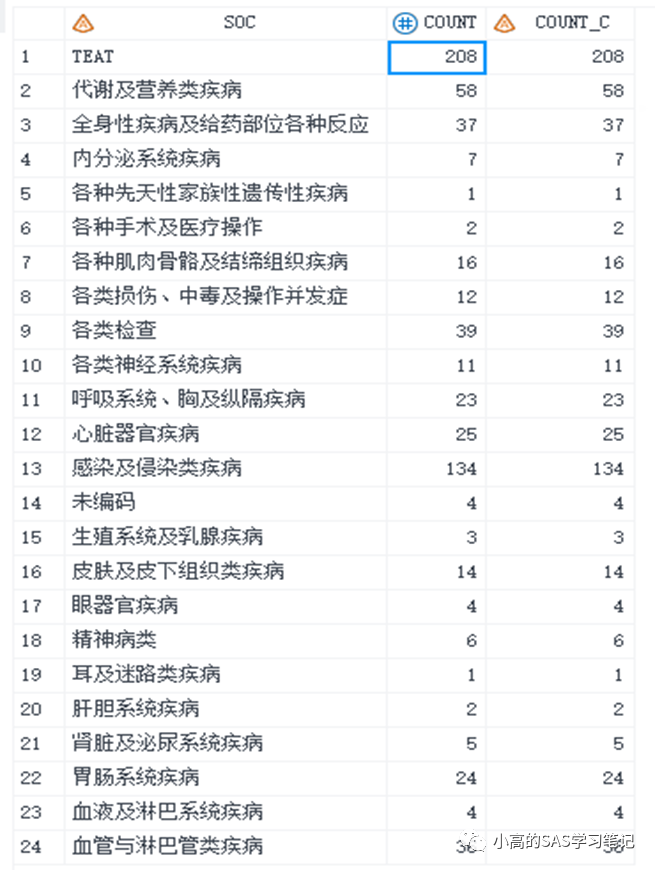
通常我们在处理此类问题时会想到用proc sort来对其进行排序
proc sort data=test out =test1 ;
by descending count soc;
run;
/ 结果如下: /
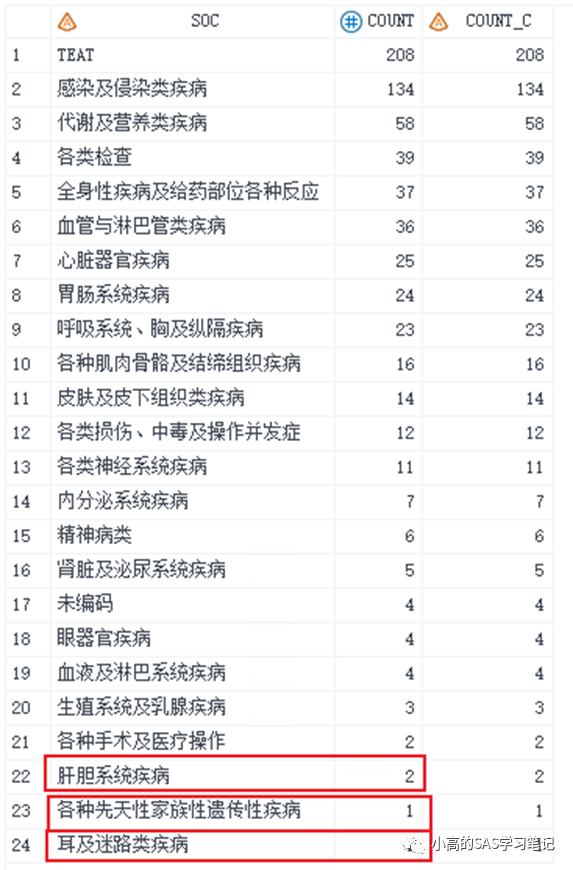
红框部分“肝胆系统疾病”的例次为2,排在“各种先天性家族性遗传性疾病”的前面似乎没什么问题,但是接下来的两个红框的例次都为1,此时应按照SOC拼音首字母排序,但是“各“的首字母应在”耳“的的后面,但是却排在了前面,所以可以肯定的是用上述程序想要对SOC按拼音排序肯定是行不通的!
/ 解决方案如下: /
proc sort data=test out =test1 sortseq=linguistic(locale=zh_CN collation=PINYIN);
by descending count soc;
run;
其实方法很简单,用sort过程步里面的选项linguistic(locale=zh_CN collation=PINYIN);就可以实现了,大家可以试一下。得到的数据集如下。
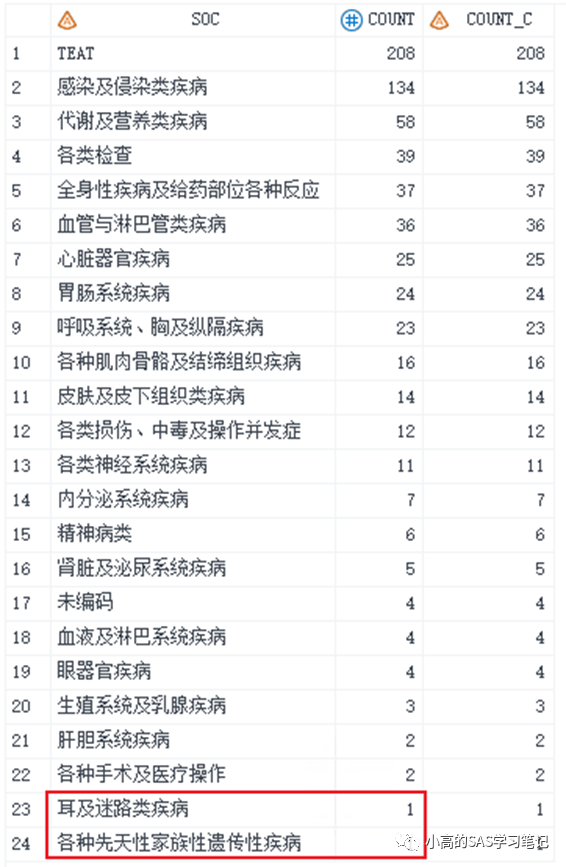
但是经过多次实验,上述的option是无法识别多音字的,多音字的时候,系统会默认按照出现最早的那个拼音字母排序。
在此举一个例子:“咳嗽”。“咳”这个字是多音字,有“hai” 和“ke“两个读音,系统会优先选择hai这个读音,因为h在k的前面。这样排序下来,可能会导致有些多音字没有按照我们的习惯读音来排序。提醒大家注意。
(2)字符型变量的数字排序
接着用上面的数据集举例:count_c为字符型变量,但是存放的是数字,如果直接用proc sort对count_c排序,得到的结果并不是我们想要得到的。
data test;
set order;
count_c=strip(put(count,best.));
run;
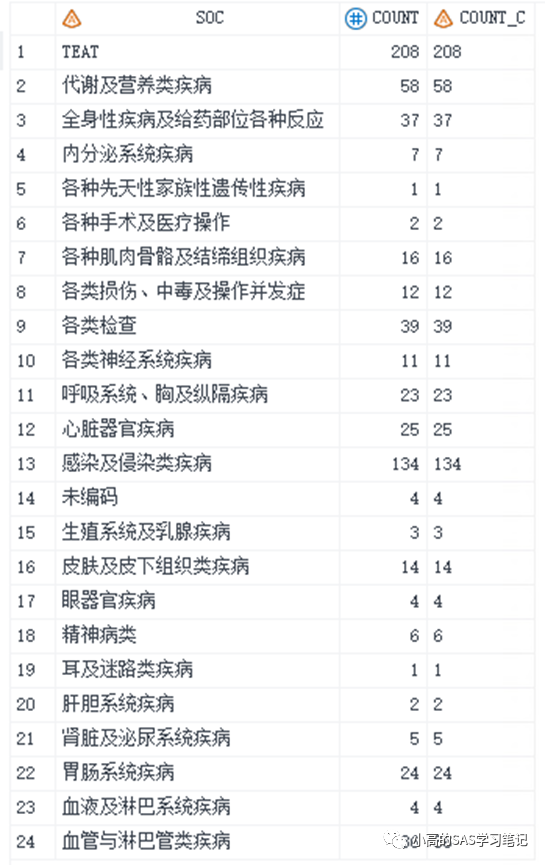
proc sort data=test out =test1 ;
by count_c;
run;
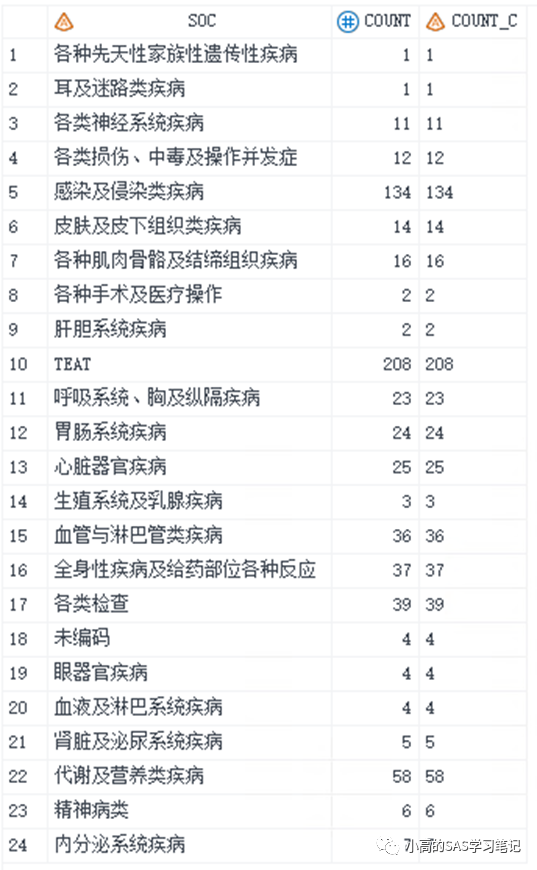
/ 解决方案如下: /
procsort data=test out =test1 sortseq=linguistic(numeric_collation=on);
by count_c;
run;
用sort过程步里面的sortseq=linguistic(numeric_collation=on)就可以实现了。得到的数据集如下,大家可以自己对比,跟用数值型结果count排序的结果是一样的。