
近些年来,数据库国产化成为大的趋势,涌现出一批数据库厂商。这些产品或基于开源构建、或全新自研,通过较短时间的发展取得了不俗的成绩。近期受邀对国产数据库-YashanDB的最新版本进行了评测,进而对这一新兴国产数据库有了较完整的认识,也为我们国产数据库取得进步感到欣喜。后续的测试内容,是基于 YashanDB 最新版本-v23.1版本进行的测试。感兴趣的同学,也可以通过如下链接获取免费版本进行测试。
下载链接:http://download.yashandb.com。
一、YashanDB 简要介绍
崖山数据库管理系统(YashanDB)是深圳计算科学研究院在经典数据库理论基础上,融入新的原创理论,自主设计、研发的新型数据库管理系统。第一次看到YashanDB的架构及能力,还是挺惊讶的,感觉是一个集“Oracle单机+DataGuard+RAC+分布式MPP(Shared-Nothing)”于一身的全面手。为了更好的理解,我简单列个表格说明下。
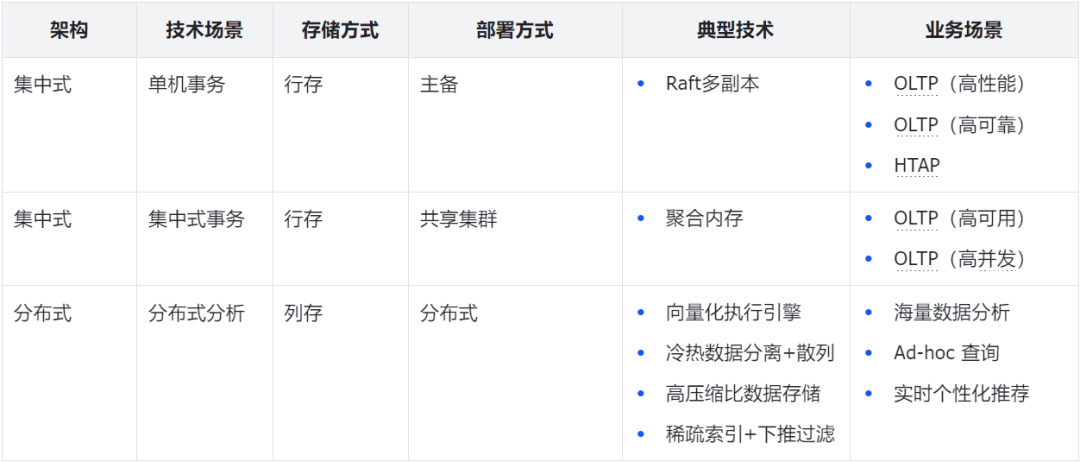
1、多部署架构
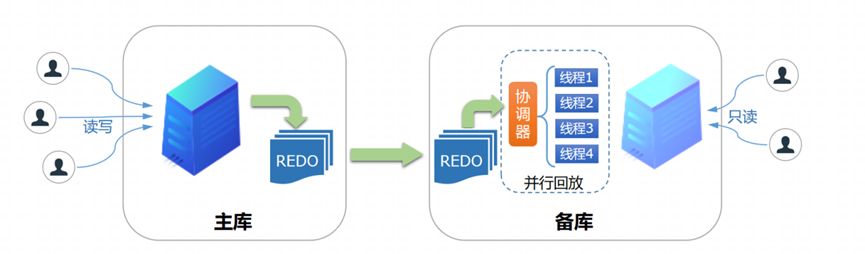
(1)主备架构
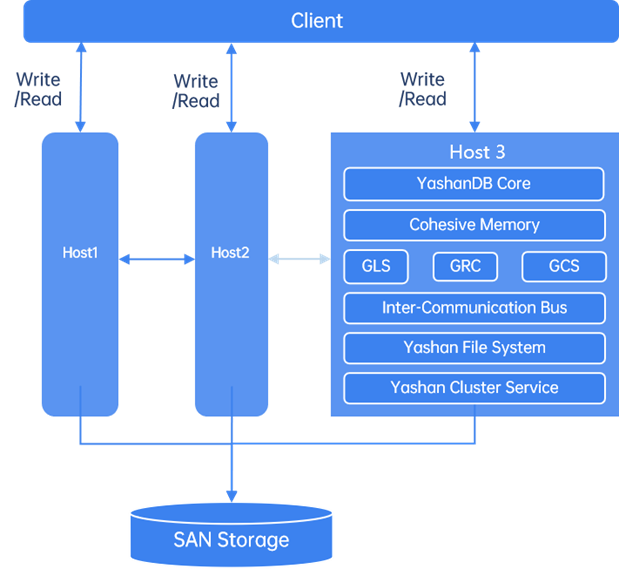
(2)共享集群架构
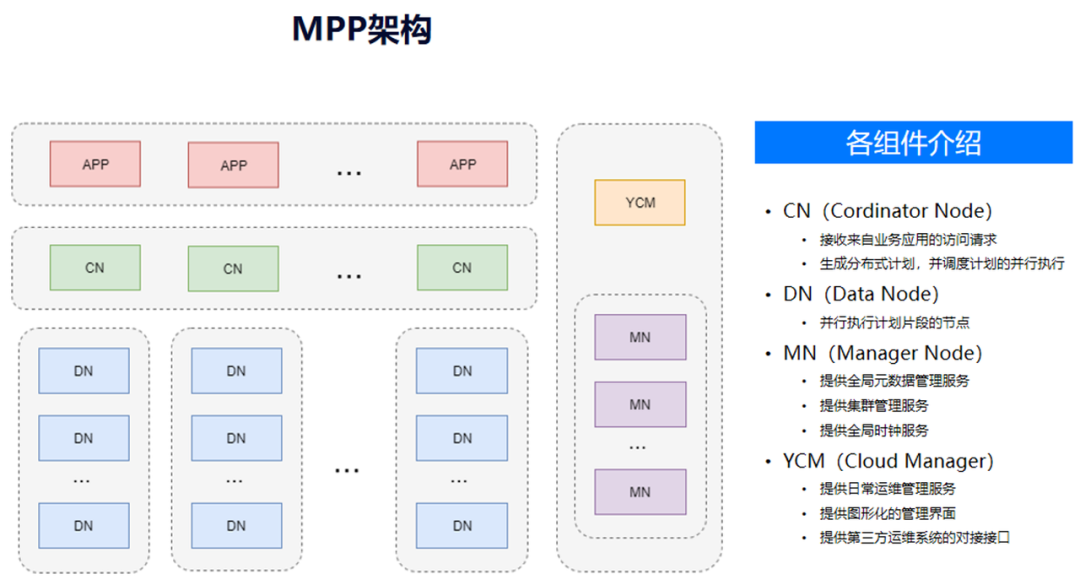
(3)分布式架构
2、多存储引擎
存储引擎是数据库核心部件之一,YashanDB通过不同的存储引擎适应不同的应用场景,以获得面向在线交易场景的高效事务处理能力,面向实时分析场景的事务与分析均衡能力,和面向海量稳态数据分析场景的高性能。基于不同的存储引擎,YashanDB支持的表类型有HEAP表,TAC表和LSC表。
- HEAP Table:行存表,主打OLTP场景。
- TAC Table (Transaction Analytics Columnar Table) :列存表,主打实时分析场景。
- LSC Table (Large-scale Storage Columnar Table):列存表,主打海量稳态数据的交互式分析场景。
3、多计算引擎
作为SQL引擎的核心组件,YashanDB的优化器采用CBO(Cost Based Optimizer)优化模式,基于统计信息,计算数据访问和处理所需要的代价,选择代价最低的方案生成执行计划。另外YashanDB 支持多种计算引擎,包括基于火山模型的执行引擎、向量化执行引擎及PL/SQL 引擎。针对大数据量下的列计算,YashanDB采用向量化执行模型,利用SIMD原理对某一列数据进行批量处理和计算,提高CPU利用率,大批量地减少程序循环。PL/SQL为数据库内部引擎,能够灵活高效地访问数据库对象,其语法基于SQL语言扩展,可编程性强,支持用户将业务逻辑下沉到数据层,更接近数据更高效,并可通过多级封装实现安全、隔离、简洁的接口供多应用系统调用。
4、多发行版本
YashanDB 也支持多种发行版本,满足不同需求。
- 个人版:YashanDB面向个人用户推出的免费试用版本,除不支持多模数据 类型、高级安全能力、数据库集群等企业级功能,该版本包含YashanDB数据库所有基础核心能力,支持单机主备部署形态,配套开发者工具;同时对最大连接数、表空间限额、列存、运维和数据迁移工具等做了限制。供个人用户或开发者用于学习、测试、开发用途。
- 标准版:YashanDB面向小规模用户推出的商业版本,该版本价格适中,除不支持多模数据类型、高级安全能力等企业级功能,该版本包含YashanDB数据库所有基础核心能力,支持单机主备、分布式、集群部署形态,配套完整数据迁移和监控运维工具,可以为政府或中小企业提供支持其操作所需的基本能力。
- 企业版:YashanDB面向大规模用户推出的商业版本,该版本包含YashanDB数据库完整核心能力,支持PB级海量数据存储和大量的并发用户,支持模数据类型、高级安全能力,支持单机主备、分布式、集群部署形态,配套完整数据迁移和监控运维工具,可以满足支撑各类企业应用。
二、 YashanDB 新版本评测
YashanDB 功能很多,覆盖多种架构及形态,可满足多种场景。受个人精力所限,此次评测仅针对发布版本的亮点功能-Oracle兼容性,进行了简单测试。从 Oracle DBA 角度来看,YashanDB 与 Oracle 的兼容度颇高,产品无论从设计理念、到核心功能、再到生态工具,都兼顾了 Oracle 的能力及操作习惯,甚至在部分能力上还有所增强。因此无论是使用者、开发者、管理者等角度看,相对上手的难度都不大。当然 Oracle 兼容性本身功能也是很复杂,可参考我之前写的文章,想做到完全兼容是不太现实的。下面挑选了部分对比项进行评测,其中部分内容通过官网文档内容说明,未做进一步测试。特别声明:以下测试结果仅代表个人意见,不作为产品选型评估依据。
1、数据类型
数据类型部分,情况则相对复杂。Oracle 支持的数据类型范围较广,YashanDB 支持了大部分数据类型,但在处理精度、存储空间等方面与Oracle还是有所区别。下面针对主要的数据类型进行了测试。
-- 测试字符类型
SQL> create table test_char(
country_id char,
city_id nchar(2),
address varchar2(4000),
name nvarchar2(40)
);
Succeed.
SQL> insert into test_char values ('1', '11', '北京市海淀区', '张三');
1 row affected.
SQL> select * from test_char;
COUNTRY_ID CITY_ID ADDRESS NAME
---------- --------- ------------------------ -------------------------------------
1 11 北京市海淀区 张三
-- 测试数字类型
SQL> create table test_num(
n1 number,
n2 number(38),
n3 number(9,2),
n4 int,
n5 smallint,
n6 decimal(5,2),
n7 float,
n8 float(2),
n9 real,
n10 binary_float,
n11 binary_double
);
Succeed.
SQL> insert into test_num values (1.23, 123, 7456123.89, 573, 34, 673.43, 34.1264, 56.2, 23.231, 12.34, 34.56);
1 row affected.
SQL> select * from test_num;
N1 N2 N3 N4 N5 N6 N7 N8 N9 N10 N11
----------- ----------- ----------- ------------ -------- ----------- ----------- ----------- ----------- ----------- -----------
1.23 123 7456123.89 573 34 673.43 3.413E+001 5.62E+001 2.323E+001 1.234E+001 3.456E+001
1 row fetched.
SQL> insert into test_num values (1.23, 123, 7456123.89, 573, 34, 673.43, 34.1264, 56.2, 23.231, 12.34f, 34.56d);
select * from test_num;
[1:98]YAS-04105 invalid number character f
// 在Oracle中可以使用f或F表示前面是个浮点数,目前YashanDB还不支持这种写法。
-- 扩展类型
SQL> create table test_long_varchar(a varchar2(8000));
Succeed.
// YashanDB还针对部分数据类型,支持了更大的值域范围,如示例中的VARCHAR2类型。
-- 测试日期/时间类型
SQL> create table test_date(
t1 date,
t2 timestamp(6),
t3 interval year(3) to month,
t4 interval day(3) to second(6)
);
Succeed.
SQL> insert into test_date values(sysdate,sysdate,INTERVAL '1' YEAR,INTERVAL '1' DAY);
1 row affected.
SQL> select * from test_date;
T1 T2 T3 T4
------------- ---------------------------------- --------------- -----------------------
2023-10-27 2023-10-27 16:52:49.000000 +01-00 +01 00:00:00.000000
SQL> create table test_date_timezone(
t1 timestamp(9) with time zone,
t2 timestamp with local time zone
);
[2:17]YAS-04209 unexpected word with
// 目前YashanDB还不支持带有时区的类型
-- 测试布尔型
SQL> create table test_bool ( a boolean);
Succeed.
SQL> insert into test_bool values(true);
1 row affected.
SQL> insert into test_bool values(false);
1 row affected.
SQL> select * from test_bool;
A
--------------------
true
false
// YashanDB 增加了 Oracle 不支持的布尔类型。
-- 测试大对象类型
SQL> create table test_bigfile(
f1 long,f2 blob,f3 clob,f4 nclob,f5 bfile);
[2:1]YAS-04229 invalid datatype
SQL> create table test_bigfile(
f1 blob,f2 clob);
Succeed.
SQL> insert into test_bigfile (f1, f2) values ('1', '2');
1 row affected.
SQL> select * from test_bigfile;
F1 F2
---------------------------------------------------------------- ----------------------------------------------------------------
01 2
1 row fetched.2、字符集及排序
字符集方面,常见的中文字符集(gbk、gb18030)及utf8系列字符集是支持重点。从官网上查看YashanDB支持的字符集,具体如下。针对字符集排序方面,YashanDB 支持部分Oracle排序能力,还有部分尚不支持。
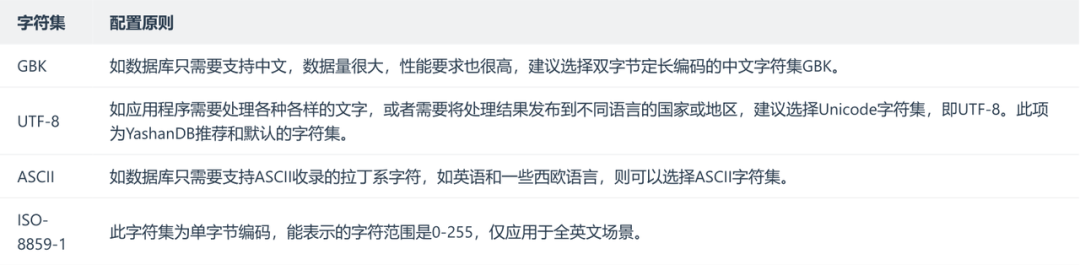
-- 查看当前字符集
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------------------
UTF8
-- 测试排序
SQL> create table test_sort(name varchar2(20));
Succeed.
SQL> insert into test_sort values('张三');
SQL> insert into test_sort values('李四');
SQL> select * from test_sort;
NAME
---------------------
张三
李四
SQL> SELECT name FROM test_sort ORDER BY NLSSORT(name,'NLS_SORT=SCHINESE_PINYIN_M');
NAME
---------------------
李四
张三
-- 按偏旁部首排序(不支持)
SQL> SELECT name FROM test_sort ORDER BY NLSSORT(name,'NLS_SORT=SCHINESE_RADICAL_M');
[3:23]YAS-04352 invalid NLS parameter string used in SQL function
-- 按笔画排序(不支持)
SQL> SELECT name FROM test_sort ORDER BY NLSSORT(name,'NLS_SORT=SCHINESE_STROKE_M');
[3:23]YAS-04352 invalid NLS parameter string used in SQL function3、数据库对象
在数据库对象方面,Oracle 支持非常丰富的对象类型,包括但不限于表、索引、分区、视图、序列、同义词、触发器、DB Link等等。YashanDB 支持了大部分数据类型,支持部分的对象尚有部分能力与Oracle还是有所区别。
-- 【测试表】
---- 堆表
SQL> create table test_heap ( id int,name varchar2(10));
Succeed.
-- 索引组织表(不支持)
SQL> create table test_iot(id varchar2 (10),name varchar2(20),
constraint pk_id primary key(id)
) organization index;
[6:14]YAS-04247 invalid table type
-- 簇表(不支持)
SQL> create cluster test_cluster(id number);
[1:16]YAS-04115 "DATABASE" expected but missing
-- 临时表
SQL> create global temporary table test_temp_tran (
tid number(3), tname varchar2(30)
) on commit delete rows;
Succeed.
SQL> create global temporary table test_temp_sess(
tid number(3), tname varchar2(30)
) on commit preserve rows;
Succeed.
SQL> create private temporary table yas$ptt_privatetemtable(c1 int,c2 int);
Succeed.
// YashanDB还支持一种新的临时表类型-private temporary。
// 该语句只作用于单机HEAP/TAC表,用于指定创建的表为私有临时表。
// 在某个会话中创建的私有临时表,其表结构及数据只对本会话可见。
// 私有临时表的名称必须为YAS$PTT_开头。
--压缩表
SQL> create table test_compress(id number,name varchar2(20)) compress;
Succeed.
-- 分区
SQL> create table test_partition(product_id varchar2(5), sales_count number(10,2))
partition by range(sales_count)
(
partition p1 values less than(1000),
partition p2 values less than(2000),
partition p3 values less than(3000)
);
SQL> SELECT PARTITION_NAME,HIGH_VALUE FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='TEST_PARTITION';
PARTITION_NAME HIGH_VALUE
------------------- ----------------
P1 1000
P2 2000
P3 3000
SQL> insert into test_partition values('1',600);
1 row affected.
SQL> insert into test_partition values('2',1000);
1 row affected.
SQL> insert into test_partition values('3',2300);
1 row affected.
SQL> insert into test_partition values('4',6000);
YAS-02115 partition key does not map to any partition
SQL> commit;
SQL> select * from test_partition partition(p1);
PRODUCT_ID SALES_COUNT
---------- -----------
1 600
-- 增加一个分区
SQL> alter table test_partition add partition p4 values less than(maxvalue);
SQL> insert into test_partition values('4',6000);
1 row affected.
SQL> SELECT PARTITION_NAME,HIGH_VALUE FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='TEST_PARTITION';
PARTITION_NAME HIGH_VALUE
------------------- ----------------
P1 1000
P2 2000
P3 3000
P4 maxvalue
-- 复合分区(List+Hash)
CREATE TABLE TEST_LIST_HASH (vl1 varchar2(20),vl2 number(12))
PARTITION BY LIST (vl1)
SUBPARTITION BY HASH (vl2)
SUBPARTITION TEMPLATE
(
SUBPARTITION SP1,
SUBPARTITION SP2,
SUBPARTITION SP3,
SUBPARTITION SP4
)
(
PARTITION P1 VALUES ('MIN', 'HOUR','SECOND'),
PARTITION P2 VALUES ('DAY', 'MONTH','YEAR'),
PARTITION P3 VALUES (DEFAULT)
);
-- 【索引】
---- BTree索引
SQL> create table test_index( a int,b int,c int,d int);
Succeed.
SQL> create index idx_test_a on test_index(a);
Succeed.
SQL> create index idx_test_ab on test_index(a,b);
Succeed.
SQL> create index idx_test_c on test_index(c desc);
Succeed.
-- Bitmap索引(不支持)
SQL> create table test_bitmap_index(a int,b int);
Succeed.
SQL> create bitmap index on test_bitmap_index(a);
[1:8]YAS-04225 invalid word bitmap
-- 基于函数的索引
SQL> create table test_fbi(a int,b int);
Succeed.
SQL> create index idx_fbi on test_fbi(abs(a));
Succeed.
SQL> explain plan for select * from test_fbi where abs(a)=1;
+----+--------------------------------+----------------------+------------+----------+
| Id | Operation type | Name | Owner | Rows |
+----+--------------------------------+----------------------+------------+----------+
| 0 | SELECT STATEMENT | | | |
| 1 | TABLE ACCESS BY INDEX ROWID | TEST_FBI | HFUSER1 | |
|* 2 | INDEX RANGE SCAN | IDX_FBI | HFUSER1 | 100|
+----+--------------------------------+----------------------+------------+----------+-- 视图SQL> create table test_view( a int,b int);
Succeed.
SQL> insert into test_view values(1,1);
SQL> insert into test_view values(1,1);
SQL> insert into test_view values(2,2);
SQL> create view v1_simple as select * from test_view where a=1;
Succeed.
SQL> create view v2_complex as select a,count(*) cnt from test_view group by a;
Succeed.
SQL> select * from v1_simple;
A B
------------ ------------
1 1
1 1
SQL> select * from v2_complex;
A CNT
------------ ---------------------
1 2
2 1
SQL> update v1_simple set b=3;
[1:8]YAS-02012 table or view does not exist
// 视图更新还不支持
-- 序列
SQL> create sequence test_seq1 increment by 2 start with 100;
Succeed.
SQL> select test_seq1.currval,test_seq1.nextval from dual;
TEST_SEQ1.CURRVAL TEST_SEQ1.NEXTVAL
----------------- -----------------
100 100
SQL> /
TEST_SEQ1.CURRVAL TEST_SEQ1.NEXTVAL
----------------- -----------------
102 102
-- 同义词
SQL> create or replace synonym test_syn for user_tables;
Succeed.
-- 触发器
SQL> create table test_trigger(a int,b int);
Succeed.
SQL> create or replace trigger test_trigger1
before insert on test_trigger
for each row
begin
:new.b:=:new.a+100;
end;
/
SQL> insert into test_trigger(a) values(1);
SQL> select * from test_trigger;
A B
------------ ------------
1 101
-- 存储过程
SQL> create or replace procedure test_procas
begin
dbms_output.put_line('hello word');
end;
/
Succeed.
SQL> set serveroutput on
SQL> call test_proc();hello word
-- DB Link
SQL> create user hfuser2 identified by 123456;
SQL> grant dba to hfuser2;
SQL> conn hfuser2/123456
SQL> create database link test_lnk connect to hfuser1 identified by 123456 using '172.16.31.8:1688';
Succeed.
SQL> select * from test_partition@test_lnk;
PRODUCT_ID SALES_COUNT
---------- -----------
1 600
2 1000
3 2300
4 6000
SQL> insert into test_partition@test_lnk values(5,700);
1 row affected.
SQL> select * from test_partition@test_lnk;
PRODUCT_ID SALES_COUNT
---------- -----------
1 600
5 700
2 1000
3 2300
4 6000
-- 【测试表】4、内置函数
函数部分,Oracle支持数百种函数,可以说极大丰富了数据库处理数据的能力。YashanDB 兼容支持了大部分函数,这样可以大幅降低代码改造的工作量。
-- 数学函数
SQL> SELECT ABS(-5) AS abs_test FROM DUAL;
ABS_TEST
---------------------
5
SQL> select cos(0) from dual;
COS(0)
-----------
1.0E+000
SQL> select acos(-1) from dual;
ACOS(-1)
-----------
3.142E+000
SQL> SELECT MOD(15, 4) AS mod_test FROM DUAL;
MOD_TEST
---------------------
3
-- 日期函数
SQL> SELECT SYSDATE AS sysdate_test FROM DUAL;
SYSDATE_TEST
--------------------------------
2023-10-16
SQL> SELECT DATE('2022-08-01') AS date_test FROM DUAL;
DATE_TEST
--------------------------------
2022-08-01
SQL> SELECT EXTRACT(MONTH FROM SYSDATE) AS extract_test FROM DUAL;
EXTRACT_TEST
------------
10
SQL> SELECT TRUNC(SYSDATE, 'MONTH') AS trunc_test FROM DUAL;
TRUNC_TEST
--------------------------------
2023-10-01
-- 字符函数
SQL> SELECT LENGTH('Hello, World!') AS length_test FROM DUAL;
LENGTH_TEST
---------------------
13
SQL> SELECT SUBSTR('Hello, World!', -4) AS substr_test FROM DUAL;
SUBSTR_TEST
-----------
rld!
SQL> SELECT INSTR('Hello, World!', 'o') AS instr_test FROM DUAL;
INSTR_TEST
---------------------
5
SQL> SELECT UPPER('Hello, World!') AS upper_test FROM DUAL;
UPPER_TEST
-----------------
HELLO, WORLD!
SQL> SELECT TRIM(' Hello, World! ') AS trim_test FROM DUAL;
TRIM_TEST
-----------------
Hello, World!
-- 其他函数
SQL> SELECT NVL('true', 'false') AS nvl_test FROM DUAL;
NVL_TEST
--------
true
SQL> SELECT USERENV('CLIENT_INFO') res FROM DUAL;
RES
----------------------------------------------------------------
user: HFUSER1
program path: /data1/yashan/yasdb_home/yashandb/23.1.0.309/bin/yasql
SQL> SELECT DECODE('',1,1,2) res1,
DECODE(1,1,1,'1',2,3) res2,
DECODE(1,'',1,'1',2,3) res3,
DECODE('','',1,3) res4
FROM DUAL;
RES1 RES2 RES3 RES4
------------ ------------ ------------ ------------
2 1 2 1
SQL> SELECT SYS_CONTEXT('USERENV', 'IP_ADDRESS') res FROM DUAL;
RES
----------------------------------------------------------------
172.16.31.85、SQL语法
SQL 语法部分,是 Oracle 颇为复杂的部分,也是很多后续改造迁移工作的重点难点。这部分涉及的情况比较多,仅做了部分简单的测试。
SQL> select * from test1;
A B
------------ ------------
1 1
2 2
3 3
SQL> select * from test2;
A B
------------ ------------
1 1
2 2
4 4
-- 表连接(ANSI写法)
SQL> select * from test1 full outer join test2 on test1.a=test2.a;
A B A B
------------ ------------ ------------ ------------
1 1 1 1
2 2 2 2
4 4
3 3
-- 表连接(Oracle方言)
SQL> select * from test1,test2 where test1.a(+)=test2.a;
A B A B
------------ ------------ ------------ ------------
1 1 1 1
2 2 2 2
4 4
-- 子查询
SQL> select * from test1 where test1.a in (select test2.a from test2);
A B
------------ ------------
1 1
2 2
-- 窗口函数
SQL> select test1.*, rank() over(order by test1.a desc) as ranks
from test1;
A B RANKS
------------ ------------ ---------------------
3 3 1
2 2 2
1 1 3
-- 聚合函数
SQL> select a from test1 group by a having count(*)<2;
A
------------
1
2
3
-- 集合查询
SQL> select * from test1 minus select * from test2;
A B
------------ ------------
3 3
-- 使用伪列
SQL> select * from test1 where rownum<2;
A B
------------ ------------
1 1
SQL> select rowid,* from test1;
ROWID A B
---------------------- ------------ ------------
2281:4:0:212:0 1 1
2281:4:0:212:1 2 2
2281:4:0:212:2 3 36、过程化语言
过程化语言,是指在数据库端处理数据的一种语言,也是很多国产数据库的痛点。从用户角度来看,过程化语言确实大大丰富了数据处理能力,是一种不可或缺的能力。YashanDB 这方面做了很大程度的兼容,常用的过程化语言用法都支持。
-- 包与存储过程
SQL> create package my_package as
procedure my_procedure (
p_input_param in integer,
p_output_param out integer
);
end my_package;
/
Succeed.
SQL> create package body my_package as
procedure my_procedure (
p_input_param in integer,
p_output_param out integer
) as
begin
p_output_param := p_input_param * 2;
end my_procedure;
end my_package;
/
Succeed.
SQL> set serveroutput on
SQL> declare
v_output_param integer;
begin
my_package.my_procedure(10, v_output_param);
dbms_output.put_line('output parameter value: ' || v_output_param);
end;
/
output parameter value: 20
PL/SQL Succeed.
-- Java UDF
SQL> create or replace library ya_lib is '/home/yashan/example/UDFexample.class';
Succeed.
$ cat UDFexample.java
package example;
public class UDFexample {
public static String execJdbcexample(int ctrls) {
switch (ctrls) {
case 1:return "Hello";
case 2:return "World";
default:return "!";
}
}
public static void main(String[] args) {
String a = execJdbcexample(1);
}
}
$ javac UDFexample.java
$ ls -lrt
-rw-rw-r--. 1 yashan yashan 322 Oct 31 11:44 UDFexample.java
-rw-rw-r--. 1 yashan yashan 477 Oct 31 11:45 UDFexample.class
SQL> CREATE OR REPLACE FUNCTION udf_func_java(argu INT) RETURN VARCHAR IS
LANGUAGE java
NAME 'example.UDFexample.execJdbcexample(int) return string'
LIBRARY ya_lib;
/
Succeed.
SQL> SELECT udf_func_java(1) FROM dual;
UDF_FUNC_JAVA(1)
----------------------------------------------------------------
Hello
SQL> SELECT udf_func_java(2) FROM dual;
UDF_FUNC_JAVA(2)
----------------------------------------------------------------
World7、数据字典/系统视图
数据字典,是元数据的存储。系统视图,则是反映系统运行状态的一个窗口。YashanDB 提供了动态视图和系统视图支持。其中,动态视图为系统提供的以V$、GV$或DV$开头的视图,用于实时展现正处于数据库运行中的各项数据,尤其与性能相关数据,用户通过查询这些视图,对系统进行管理和优化。
- V$视图:本地动态视图,查询当前所在实例节点的数据,在单机、分布式、共享集群部署中的表现一致。
- GV$视图:全局动态视图,在共享集群部署中,GV$视图查询的是所有实例数据进行汇聚的结果,在单机/分布式部署中,GV$视图等同于V$视图,查询的是本地数据。
- DV$视图:分布式动态视图,DV$视图只在分布式部署中存在,查询的是所有节点数据进行汇聚的结果。
-- 动态视图
SQL> select database_name,log_mode,open_mode,status,current_scn from v$database;
DATABASE_NAME LOG_MODE OPEN_MODE STATUS CURRENT_SCN
------------------ ----------------- ----------------- ----------- ---------------------
yashandb ARCHIVELOG READ_WRITE NORMAL 489941942425038848
SQL> select startup_time,host_name,data_home,instance_name from v$instance;
STARTUP_TIME HOST_NAME DATA_HOME INSTANCE_NAME
---------------------------- ------------- ----------------------------------- -------------------
2023-10-12 17:31:41.069135 host-23-8 /data1/yashan/yasdb_data/db-1-1 yasdb
SQL> select name, thread_id,status from v$process;
NAME THREAD_ID STATUS
--------------------------------- --------------------- ---------------------------------
TIMER 96616 Working
BUFFER_POOL 96617 Working
PRELOADER 96618 Working
PRELOADER 96619 Working
SMON 96620 Working
CKPT 96621 Working
DBWR 96622 Working
DBWR 96623 Working
SCHD_TIMER 96624 Working
TCP_LSNR 96625 Working
LISTENER_LOG 96627 Working
TCP_LSNR 96628 Working
TCP_LSNR 96629 Working
MMON 96630 Working
JOB_QUEUE 96631 Working
RD_ARCH 96636 Working
ARCH_DATA 96637 Working
HEALTH_MONITOR 96639 Working
PARAL_WORKER_0 96641 Working
PARAL_WORKER_1 96642 Working
LOGW 96643 Working
XFMR 96644 Working
-- DBA/ALL/USER视图
SQL> select username,account_status,profile from dba_users;
USERNAME ACCOUNT_STATUS PROFILE
--------- ------------------- -----------
SYS OPEN DEFAULT
HFUSER2 OPEN DEFAULT
HFUSER1 OPEN DEFAULT
MDSYS LOCKED DEFAULT
SQL> select owner,object_type,count(*) from dba_objects group by owner,object_type order by 1,3 desc;
OWNER OBJECT_TYPE COUNT(*)
----------- --------------------- ---------
HFUSER1 TABLE 16
HFUSER1 INDEX 6
HFUSER1 TABLE PARTITION 4
HFUSER1 VIEW 2
HFUSER1 LOB 2
HFUSER1 SYNONYM 1
HFUSER1 TRIGGER 1
HFUSER1 SEQUENCE 1
HFUSER1 PROCEDURE 1
HFUSER2 UNDEFINED 18、SQL/PLSQL引擎
SQL 引擎部分,是 Oracle 内核最为强大的组件,提供如查询改写、预编译、CBO、执行计划(展示、缓存、绑定、管理)、自适应游标、提示等非常丰富的能力,可对 SQL 语句及执行做到全方位的管理。YashanDB的优化器采用CBO(Cost Based Optimizer)优化模式。优化器的目标是为SQL语句生成最有效的执行计划传递给执行器,执行计划包含数据访问路径、表连接顺序等执行算子信息。YashanDB的CBO优化器基于统计信息,计算数据访问和处理所需要的代价,选择代价最低的方案生成执行计划。其统计信息主要包括表、列、索引的统计信息,例如表的行数、列的平均长度、索引包含的列数等。统计信息有动态收集、实时收集、在线收集、定时任务及手动触发等多种收集方式,同时,可通过并行统计、抽样统计等技术加快统计效率,为优化器提供及时更新的信息。在执行算子上,支持了扫描、表连接、查询、排序、辅助、PX并行执行等多种算子。同时支持利用Hint,对优化器对算子的选择和执行方式提出干预,例如指定表扫描的方式、指定执行顺序、指定并行度等,优化器将根据这些提示,结合统计信息,生成最优的执行计划。Oracle特有的PL/SQL能力,能够灵活高效地访问数据库对象,其语法基于SQL语言扩展,可编程性强,支持用户将业务逻辑下沉到数据层,更接近数据更高效,并可通过多级封装实现安全、隔离、简洁的接口供多应用系统调用。YashanDB也支持了包括存储过程、匿名块、函数、JOB、触发器和高级包功能。这部分未做详细测试。
-- 统计信息
SQL> exec dbms_stats.gather_schema_stats('hfuser1');
PL/SQL Succeed.
SQL> select table_name,num_rows,blocks,last_analyzed,partitioned,temporary from user_tables;
TABLE_NAME NUM_ROWS BLOCKS LAST_ANALYZED PARTITIONED TEMPORARY
---------------------- ----------- ---------- ----------------- ----------- ---------
TEST_TEMP_SESS N Y
TEST_TEMP_TRAN N Y
T_PROC 0 1 2023-10-18 N N
TEST2 3 1 2023-10-18 N N
TEST1 3 1 2023-10-18 N N
TEST_TRIGGER 1 1 2023-10-18 N N
TEST_VIEW 3 1 2023-10-18 N N
TEST_FBI 0 0 2023-10-18 N N
TEST_BITMAP_INDEX 0 0 2023-10-18 N N
TEST_INDEX 3 1 2023-10-18 N N
TEST_COMPRESS 0 0 2023-10-18 N N
TEST_PARTITION 4 4 2023-10-18 Y N
TEST_HEAP 0 0 2023-10-18 N N
TEST_BIGFILE 1 1 2023-10-18 N N
TEST_DATE 1 1 2023-10-18 N N
TEST_NUM 1 1 2023-10-18 N N
TEST_CHAR 1 1 2023-10-18 N N
TEST_TBS 1 1 2023-10-18 N N SQL> select index_name,table_name,blevel,distinct_keys,status from user_indexes;INDEX_NAME TABLE_NAME BLEVEL DISTINCT_KEYS STATUS
--------------------- ---------------- ------------ ----------------- ---------
SYS_IL2248C00001$$ TEST_BIGFILE VALID
SYS_IL2248C00000$$ TEST_BIGFILE VALID
IDX_FBI TEST_FBI 0 0 VALID
IDX_TEST_C TEST_INDEX 0 0 VALID
IDX_TEST_AB TEST_INDEX 0 0 VALID
IDX_TEST_A TEST_INDEX 0 0 VALID
-- 优化器
SQL> show parameter optimizer_mode;
NAME VALUE
---------------- ----------------
0 rows fetched.
//YashanDB 目前尚不支持修改优化器行为。9、系统调优
系统调优是 DBA 常规需要完成的工作,包括实例调优、语句调优等。实例调优通常通过诊断报告进行分析后调整,语句调优通常包括查看执行计划、语句调优、结构优化等。对于不易调整的计划,也可以采用如Hint、Outline的方式进行改写。下图是 YashanDB 生成的 AWR 报告,形式上与 Oracle AWR 十分类似。通过这一报告可以快速了解快照间系统整体运行状况,当然目前 YashanDB 支持的指标还没有那么多,相信未来会不断完善。
下面是针对语句调优,可完成的一些工作。
-- 查看执行计划(EXPLAIN)
SQL> explain plan for select * from test_partition where product_id=2;
PLAN_DESCRIPTION
----------------------------------------------------------------
SQL hash value: 3275967159
Optimizer: ADOPT_C
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
| Id | Operation type | Name | Owner | Rows | Cost(%CPU) | Partition info |
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
| 0 | SELECT STATEMENT | | | | | |
| 1 | PART SCAN ALL | | | 1| 34( 0)| [0,3] |
|* 2 | TABLE ACCESS FULL | TEST_PARTITION | HFUSER1 | 1| 34( 0)| |
+----+--------------------------------+----------------------+------------+----------+-------------+--------------------------------+
Operation Information (identified by operation id):
---------------------------------------------------
2 - Predicate : filter("TEST_PARTITION"."PRODUCT_ID" = 2)
SQL> set autotrace on
SQL> select * from test_partition where product_id=2;
Execution Plan
----------------------------------------------------------------
SQL hash value: 3275967159
Optimizer: ADOPT_C
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
| Id | Operation type | Name | Owner | E - Rows | A - Rows | Cost(%CPU) | A - Time | Loops | Memory | Disk | Partition info |
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
| 0 | SELECT STATEMENT | | | | | | | | | | |
| 1 | PART SCAN ALL | | | 1| | 34( 0)| | | | | [0,3] |
|* 2 | TABLE ACCESS FULL | TEST_PARTITION | HFUSER1 | 1| | 34( 0)| | | | | |
+----+--------------------------------+----------------------+------------+----------+----------+-------------+----------+----------+----------+----------+--------------------------------+
Operation Information (identified by operation id):
---------------------------------------------------
2 - Predicate : filter("TEST_PARTITION"."PRODUCT_ID" = 2)
-- 查看执行计划(AutoTrace)
SQL> set autotrace on
SQL> select count(*) from test1;
COUNT(*)
---------------------
3
Execution Plan
----------------------------------------------------------------
SQL hash value: 860157296
Optimizer: ADOPT_C
+----+----------------------+--------+---------+----------+----------+-------------+----------+----------+----------+----------+----------------+
| Id | Operation type | Name | Owner | E - Rows | A - Rows | Cost(%CPU) | A - Time | Loops | Memory | Disk | Partition info |
+----+----------------------+--------+---------+----------+----------+-------------+----------+----------+----------+----------+----------------+
| 0 | SELECT STATEMENT | | | | | | | | | | |
| 1 | AGGREGATE | | | 1| | 13( 0)| | | | | |
| 2 | TABLE ACCESS FULL | TEST1 | HFUSER1 | 3| | 13( 0)| | | | | |
+----+----------------------+--------+---------+----------+----------+-------------+----------+----------+----------+----------+----------------+
Statistics
----------------------------------------------------------------------------------------------------
11 rows fetched.
-- Hint
SQL> select * from test_index where a=2;
+----+--------------------------------+----------------------+------------+
| Id | Operation type | Name | Owner |
+----+--------------------------------+----------------------+------------+
| 0 | SELECT STATEMENT | | |
| 1 | TABLE ACCESS BY INDEX ROWID | TEST_INDEX | HFUSER1 |
|* 2 | INDEX RANGE SCAN | IDX_TEST_A | HFUSER1 |
+----+--------------------------------+----------------------+------------+
SQL> select /*+ full(test_index) */ * from test_index where a=2;
+----+--------------------------------+----------------------+------------+
| Id | Operation type | Name | Owner |
+----+--------------------------------+----------------------+------------+
| 0 | SELECT STATEMENT | | |
|* 1 | TABLE ACCESS FULL | TEST_INDEX | HFUSER1 |
+----+--------------------------------+----------------------+------------+10、安全特性
YashanDB实现了用户、角色、权限管理,支持包括三权分离等能力。特别是针对DBA关注的安全需求,如审计、防火墙、数据加密等能力也有实现。虽然相较于Oracle还有着不小的差距,如数据加密仅支持表空间,但初步安全能力都已具备,可满足日常安全需求。以用户及角色为例,简单测试了一下。
SQL> CREATE USER hfuser1 IDENTIFIED BY 123456;
Succeed.
SQL> GRANT CONNECT TO hfuser1;
Succeed.
SQL> GRANT RESOURCE TO hfuser1;
Succeed.
SQL> GRANT CONNECT,RESOURCE TO hfuser1;
YAS-02216 invalid privilege or role specified
//这点与Oracle有差异,无法单次授予多个角色权限
SQL> CONN hfuser1/123456
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> select username,user_id,account_status,default_tablespace from user_users;
USERNAME USER_ID ACCOUNT_STATUS DEFAULT_TABLESPACE
-------------- ------------ ------------------- -------------------------
HFUSER1 3 OPEN USERS11、实例管理
实例管理,是DBA日常对数据库实例的运维类操作,包括对实例状态、参数、日志、控制文件等的管理。
-- 实例启停
SQL> select status from v$instance;
STATUS
-------------
OPEN
SQL> shutdown;
Succeed.
[mys@host-23-8 ~]$ nohup yasdb open &
[1] 110817
[mys@host-23-8 ~]$ yasql sys/xxx@<ip>:<port>
YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> select status from v$instance;
STATUS
-------------
OPEN
--在线与归档日志
SQL> SELECT database_name,log_mode,open_mode FROM v$DATABASE;
DATABASE_NAME LOG_MODE OPEN_MODE
------------------- ----------------- -----------------
yashandb ARCHIVELOG READ_WRITE
SQL> SELECT * FROM v$archived_log;
NAME SEQUENCE# THREAD# RESETLOGS_ID FIRST_CHANGE#
---------------------------- ------------ ------- ------------ ---------------------
/data1/yashan/arch_0_1.ARC 1 1 0 0
/data1/yashan/arch_0_2.ARC 2 1 0 488514779900493824
/data1/yashan/arch_0_3.ARC 3 1 0 488993590743019520
/data1/yashan/arch_0_4.ARC 4 1 0 489347488660754432
/data1/yashan/arch_0_5.ARC 5 1 0 490055274011684864
/data1/yashan/arch_0_6.ARC 6 1 0 490314622336798720
/data1/yashan/arch_0_7.ARC 7 1 0 490409186952015872
/data1/yashan/arch_0_8.ARC 8 1 0 490528754307604480
SQL> select * from v$logfile;
THREAD# ID NAME BLOCK_SIZE BLOCK_COUNT USED_BLOCKS SEQUENCE# STATUS
------- ----- ----------------- ------------ ------------ ------------ ------------ ---------
1 0 /data1/redo1 4096 32768 192 9 CURRENT
1 1 /data1/redo2 4096 32768 32768 6 INACTIVE
1 2 /data1/redo3 4096 32768 2749 7 INACTIVE
1 3 /data1/redo4 4096 32768 174 8 INACTIVE
-- 参数
SQL> show parameter;
NAME VALUE
---------------------------------------------------------------- ----------------------------------------------------------------
MAX_SESSIONS 1024
MAX_WORKERS 0
MAX_PARALLEL_WORKERS 32
MAX_REACTOR_CHANNELS 0
WORK_AREA_STACK_SIZE 1024K
...
ENABLE_ARCH_DATA_IGNORE_BACKUP FALSE
176 rows fetched.
//YashanDB 包含了176个参数
SQL> alter system set MAX_SESSIONS=1000 scope=spfile;
Succeed.
--控制文件
SQL> select * from v$controlfile;
ID NAME BLOCK_SIZE FILE_SIZE_BLKS BYTES
----- ---------------------------------------------------------------- ------------ -------------- ---------------------
0 /data1/yashan/yasdb_data/db-1-1/dbfiles/ctrl1 8192 3097 25370624
1 /data1/yashan/yasdb_data/db-1-1/dbfiles/ctrl2 8192 3097 25370624
2 /data1/yashan/yasdb_data/db-1-1/dbfiles/ctrl3 8192 3097 2537062412、存储管理
YashanDB 使用与Oracle类似的层次存储,包含Tablespace-Datafile-Segment-Extent-Block多个级别。
-- 表空间管理
[mys@host-23-8 ~]$ yasql sys/xxx@<ip>:<port>
YashanDB SQL Enterprise Edition Release 23.1.0.309 x86_64
Connected to:
YashanDB Server Enterprise Edition Release 23.1.0.309 x86_64 - X86 64bit Linux
SQL> select tablespace_name from dba_tablespaces;
TABLESPACE_NAME
----------------------------------------------------------------
SYSTEM
SYSAUX
TEMP
SWAP
USERS
UNDO
SQL> create tablespace tbs_test datafile '.../dbfiles/tbs_test.dbf' size 10m autoextend on;
Succeed.
mys@host-23-8 ~]$ yasql hfuser1/<ip>:<port>
SQL> create table test_tbs ( a int) tablespace tbs_test;
Succeed.
SQL> insert into test_tbs values(1);
1 row affected.13、备份恢复
备份恢复能力是数据库的基础,也是保护数据的最重要手段。YashanDB提供了多种备份及恢复方式,有基于SQL(BACKUP、RESTORE语句)、基于工具YasRMAN(类似RMAN)或者通过图形化终端发起备份。备份支持全量及多级增量备份,同时可支持备份压缩与加密。恢复方面,支持全量及基于时点的还原,后者仅支持单机版本。下面针对备份做个简单测试
SQL> BACKUP DATABASE FULL FORMAT '/tmp/backup_full_20231017';
Succeed.
[mys@host-23-8 ~]$ ls -al /tmp/backup_full_20231017/*
-rw-r----- 1 mys mys 124387328 Oct 17 20:07 /tmp/backup_full_20231017/arch0_0_5_0.bak
-rw-r----- 1 mys mys 5632 Oct 17 20:07 /tmp/backup_full_20231017/backup_filelist
-rw-r----- 1 mys mys 16777216 Oct 17 20:07 /tmp/backup_full_20231017/backup_profile
-rw-r----- 1 mys mys 25370624 Oct 17 20:07 /tmp/backup_full_20231017/ctrl_0_0_0.bak
-rw-r----- 1 mys mys 67108864 Oct 17 20:07 /tmp/backup_full_20231017/data_0_0_0.bak
-rw-r----- 1 mys mys 67108864 Oct 17 20:07 /tmp/backup_full_20231017/data_1_0_0.bak
-rw-r----- 1 mys mys 8192 Oct 17 20:07 /tmp/backup_full_20231017/data_2_0_0.bak
-rw-r----- 1 mys mys 8192 Oct 17 20:07 /tmp/backup_full_20231017/data_3_0_0.bak
-rw-r----- 1 mys mys 67108864 Oct 17 20:07 /tmp/backup_full_20231017/data_4_0_0.bak
-rw-r----- 1 mys mys 134217728 Oct 17 20:07 /tmp/backup_full_20231017/data_5_0_0.bak
-rw-r----- 1 mys mys 134217728 Oct 17 20:07 /tmp/backup_full_20231017/data_5_0_1.bak
-rw-r----- 1 mys mys 67108864 Oct 17 20:07 /tmp/backup_full_20231017/data_5_0_2.bak14、高可用
在高可用方面,YashanDB支持多种高可用架构,包括主备模式(类似Oracle DataGuard)、共享模式(类似Oracle RAC)、分布式模式。其中主备模式支持一主多备和级联备模式(不限层级),当主机发生故障的时候,业务可以转移到备机上继续执行,降低故障对业务的影响,提高数据库的可用性。共享模式则是在共享存储与共享内存技术实现一个单库多实例的多活数据库系统。支持在线故障自动切换和故障自动恢复,集群任一实例异常都不影响正常实例对外提供的服务。分布式则是采用Shared-Nothing 架构,由管理节点组、协调节点组与数据节点组组成。这些节点部署在不同主机上,有不同的安装目录、数据目录,并且通过一些网络端口进行内部通讯或对外提供服务。此外,针对对象级的误操作等,也提供了闪回功能。受限于测试环境,未做高可用测试。
15、生态接口与工具
YashanDB 可通过很多的数据访问接口,如常见的JDBC、ODBC、C、Python、ADO.NET 等,几乎面对不同访问语言都有对应的访问接口可用。同时支持持久化框架-Mybatis、SQL开发工具(如DataGrip、DBeaver)、BI工具(如FineBI)及大数据分析工具(如Spark、Kafka等)。为了方便运维,其也支持很多独立小工具,很多如 Oracle 的工具集,如yasql(命令行管理工具)、imp/exp(导入导出工具)、yasboot(安装部署与运维工具)、yasrman(备份工具)、yasldr(文本加载工具)等。