随着分布式数据库逐步成熟,越来越多的企业开始考虑使用这一新兴架构产品。国内也诞生出一批本土的分布式数据库厂商。在众多分布式数据库产品有,有一家其技术架构、产品定位和功能亮点颇为引人瞩目,这就是来自深圳的泽拓科技及其研发的分布式数据库产品-KlustronBase(下文简称昆仑数据库)。下文是近期针对这一数据库产品,做的一些探索。
1. 初识昆仑数据库
1)产品概述
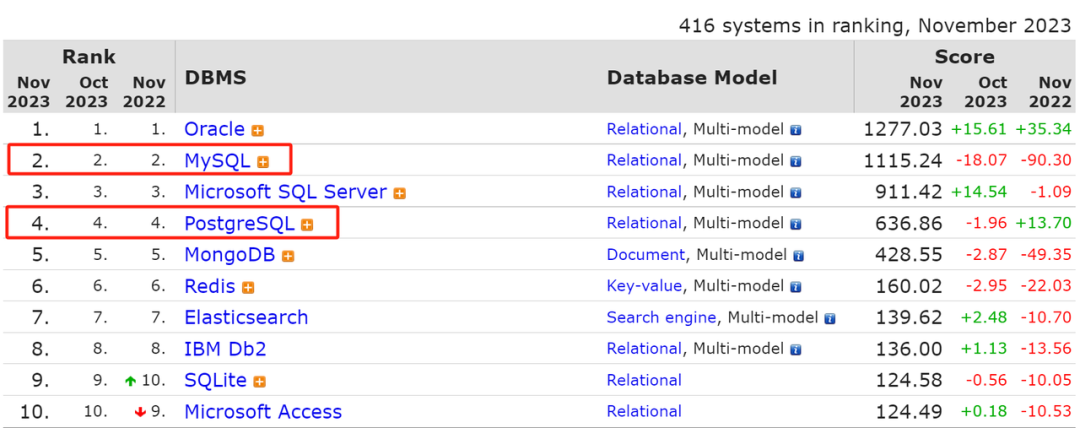
刚开始接触这一数据库产品,给我最大感觉就是其架构特点,它通过将作为流行的两款开源数据库产品组合而成。做数据库的同学都知道,MySQL、PostgreSQL 是全球最为流行的两款开源数据库,在近二、三十年的时间在全球范围内得到了广泛的应用。从下图来自 db-engines 的流行度排名来看,这两款产品排名前五,也是最为流行的开源数据库。
 图片
图片
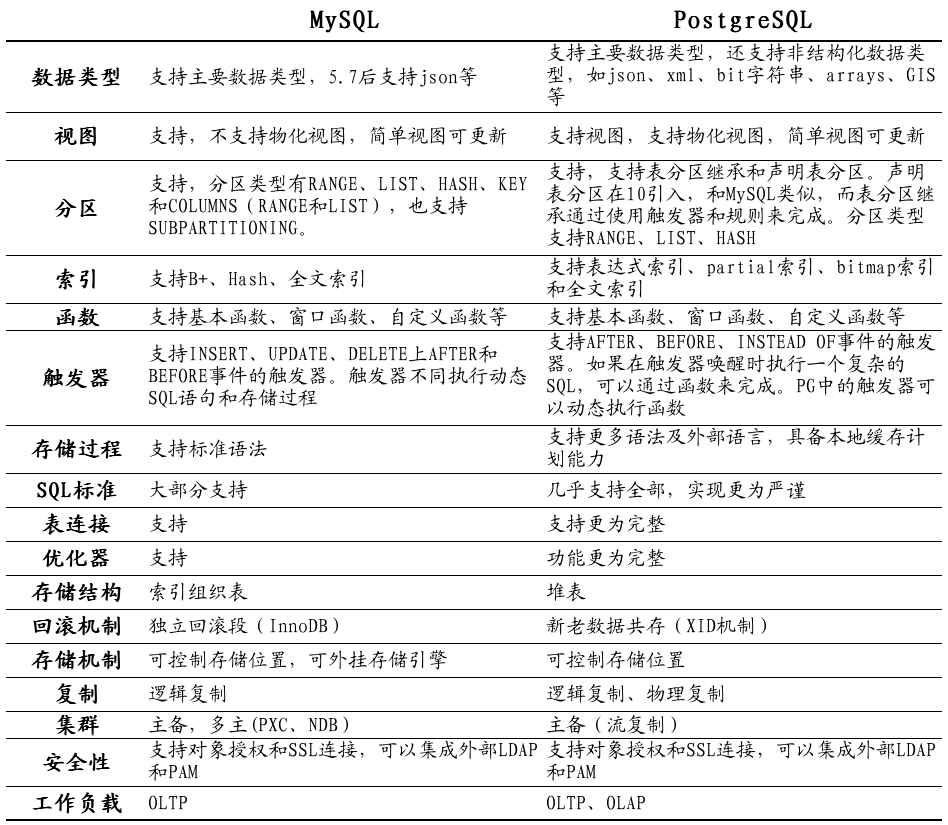
作为流行的开源数据库佼佼者,这两款产品各有其优势和特点。MySQL 数据库,在二十多年前随着互联网兴起,得到了广泛的应用,其以轻量化、简洁著称;特别是其核心的存储引擎-InnoDB,更以其稳定架构、卓越性能而成为默认存储引擎,得到大量应用。PostgreSQL 数据库,则是一种典型的学院派产品,业内常用一种说法,称其是作为最为强大的开源数据库,具备大量企业级能力(如优化器等)。可以说,两个数据库各有所长,之前也在企业不同场景发挥着重要的作用。下表是针对两种数据库的功能对比。
 图片
图片
这两类数据库各有所长,但也存在各自的短板。例如 MySQL 的优化器能力、PostgreSQL 的存储引擎的不定期 vacuum 问题。昆仑数据库的设计之初,正是充分利用开源产品的优点、规避其确定,发挥各自所长而形成的产品架构。
2)架构特点
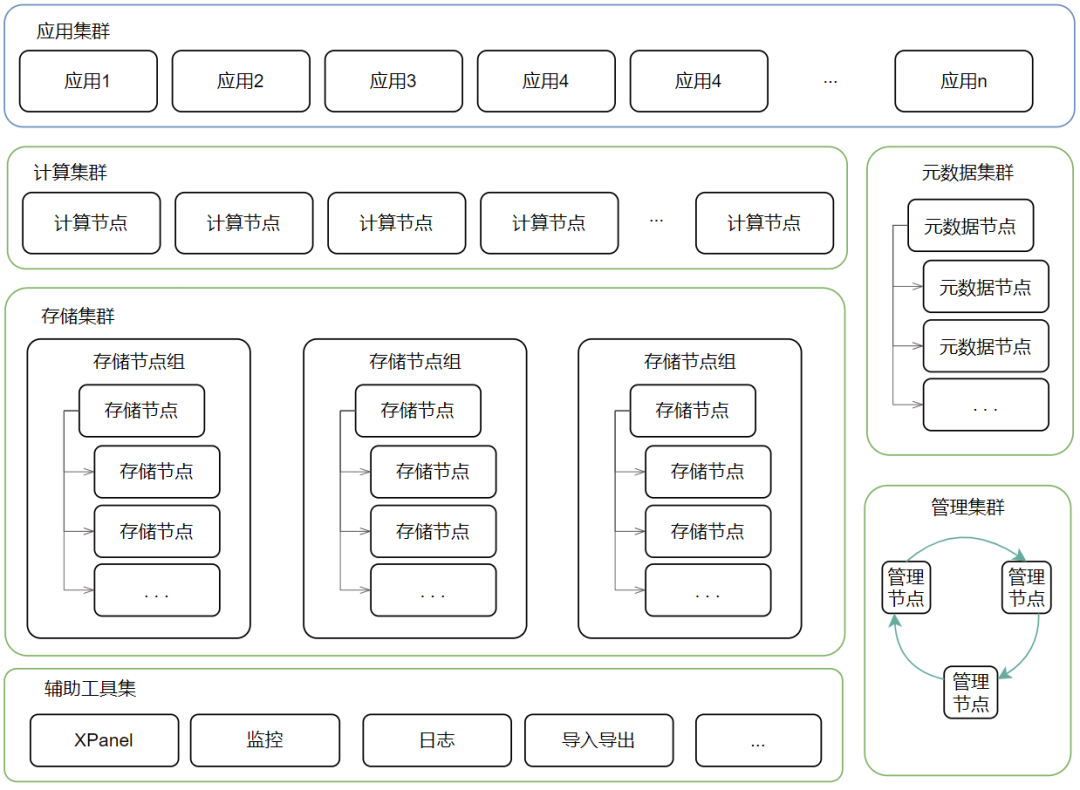
昆仑数据库的架构,是个典型的存算分离架构,跟很多国内分布式数据库产品,如TDSQL、GoldenDB是比较相似的。其共有几个部分组成:
- 计算集群,由一组无状态的计算节点组成,实现上是通过 PostgreSQL 实例增强所成。用户可以根据需要进行水平扩展,来满足更好算力的需求。
- 存储集群,由一组有状态的存储节点组组成。每个存储节点组,是一个 MySQL 的主从复制集群。用户可以根据需要进行水平扩展,即通过更多的数据分片满足更大存储空间的需求。
- 元数据集群,是整个集群的“大脑”,是由一组元数据节点组成。元数据节点集群,是一个 MySQL 的主从集群构成。其负责存储集群内的元数据等功能,并可为多个集群共享使用。
- 管理集群,是整个集群的“四肢”,是由一组管理节点组成。管理集群,是通过 raft 协议维护的一组节点,其中的备节点是作为主节点宕机后快速顶替。其与上面的元数据集群,是一对一关系,可为多个集群提供服务。
- 辅助工具集,在集群外还有一组生态工具,完成包括图形化管控、监控、日志、导入导出等工作。
 图片
图片
3)功能亮点
- 坚不可摧
作为一款分布式数据库,昆仑数据库集群在任一节点发生故障或者网络故障,甚至机房整体故障,都不会丢失或者损坏用户数据,也不会影响业务系统正常运行。其下层使用的是 MySQL 的主从复制技术。众所周知,MySQL 的主从复制技术存在一定缺陷,无法保证主从数据的强一致。昆仑数据库基于自研的 fullsync 技术,提供金融级数据一致性和高可用性。在存储主节点故障时,可在集群层面快速发现并通过主备切换快速解决。
- 弹性伸缩
昆仑数据库的计算节点与存储节点,均支持不停服的水平弹性伸缩,且不会对业务系统和逻辑以及终端用户体验造成任何影响;能够均衡地利用所有服务器的计算和存储资源来提供持续稳定的服务能力。这一特点,可方便用户的“敏态”业务,根据业务负载变化,随时调整计算与存储资源投入。
- 海纳百川
昆仑数据库应该还是业内唯一一款同时支持 MySQL 和 PostgreSQL 数据库协议和语法的产品,并可以兼容常用的编程语言等。国内很多分布式数据库都是通过开源数据库扩展而来,因而支持 MySQL、支持 PostgreSQL,但同时支持目前看仅此一家。这种良好的生态兼容性,也方便用户迁移上来。
- 极致性能
昆仑数据库在官网文档上,说明其性能大幅领先于竞品,并称确保在 TB 级别数据、数千连接、数十万 QPS 仍然可以提供高吞吐率低延时的事务处理性能。针对这一点,个人还保持谨慎态度,不同的业务模型性能表现可能差异很大,企业还是需要根据自身业务特点进行评测。
- HTAP
昆仑数据库通过其强大的优化器和独创的并行查询能力,可实现数据的在线计算。即在联机交易基础上,实现一定能力的在线分析能力,即所谓的 HTAP 能力。
- 多模混算
昆仑数据库提供了多模数据的存储与计算能力,支持包括 JSON、GIS、Vector 等类型数据的存储与计算。这对于用户构建统一承载平台无疑很有好处。
4)场景分析
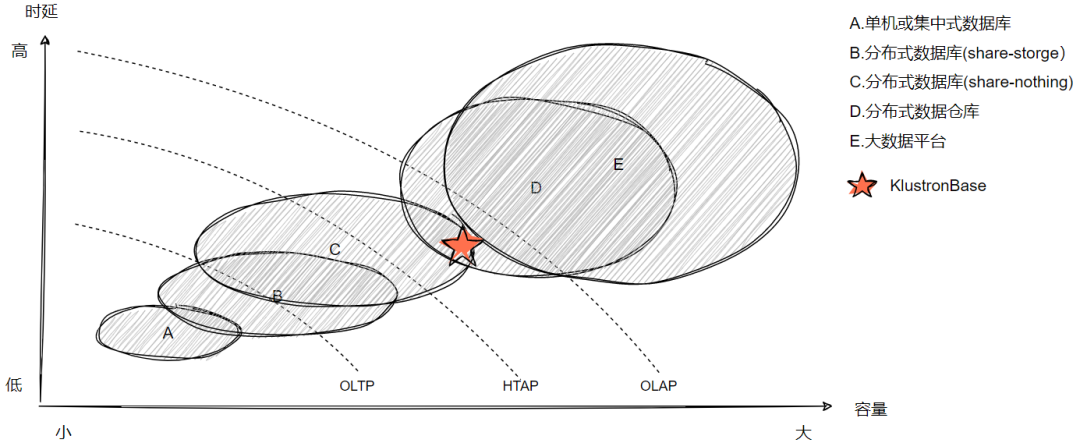
可以说国内分布式数据库非常繁多,如何在众多产品中定位、选择一款产品非常关键。这里通过一张简图进行说明,并尝试将主要技术架构路线覆盖范围及昆仑数据库所在定位进行描述。下图将用户的数据库使用场景,简单从数据容量、响应时长角度进行归类。横轴表示数据容量,越靠右规模越大;纵轴表示响应时延,越靠上时延越高。根据常规的的划分,我们可以将数据使用场景,简单分为 OLTP-联机交易、HTAP-混合负载和 OLAP-联机分析,其对应的数据规模和时延要求各有不同。从主要技术实现路线来看,可大致按照擅长的领域做下划分,如下图。其中会有部分场景上有所交叉。
 图片
图片
昆仑数据库架构上是属于 share nothing 架构,覆盖场景包括 OLTP、HTAP。其可在满足承载大规模数据容量的前提下,提供有时延保证的数据访问能力。支持多种数据分片的同时,也支持一定复杂度的在线数据分析。
2. 实践昆仑数据库
1)安装部署
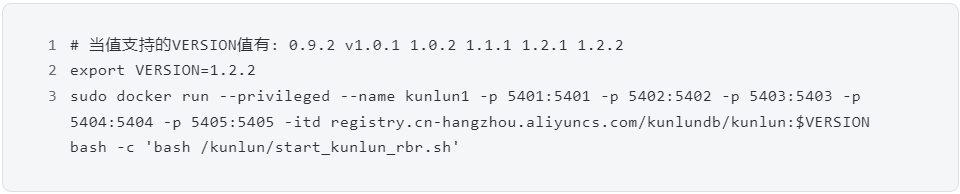
使用过分布式数据库的朋友,可能都有这样的感受。因分布式数据库组件多、节点多,安装部署非常麻烦。这也成为妨碍很多用户尝试新产品的最大阻力。昆仑数据库这方面做到不错,提供了 Docker、一键安装等多种形式。这里为了省事,直接采用 Docker 方式。
 图片
图片
2)使用体验
一个数据库的功能非常庞杂,因个人精力有限,只测试了部分功能。针对昆仑数据库,其生态兼容性特点很突出,兼容了最为流行的两款开源数据库 MySQL 和 PostgreSQL。这里所说的兼容,包括了协议、语法等多层面。下面示例就将依次使用 PostgreSQL 和 MySQL 两种方式,看看使用体验如何。首先我们通过 PostgreSQL 方式连接测试实例,看看整体集群的情况。
 图片
图片
然后在 MySQL 模式下做个简单的 CRUD,看看数据库表现如何。
 图片
图片
从上面操作可见,昆仑数据库实现了 MySQL、PostgreSQL 两种数据库的常见语法、方言及操作习惯。两个生态的用户都可以很方便的快速使用它。这无疑大大拓展了其受众用户,减低了使用门槛。作为国内分布式数据库的一员,相信昆仑数据库将在未来得到更广泛的使用,也欢迎大家关注试用 http://klustron.com