Google最强大的大模型Gemini发布了,陆续读了技术报告和一些评测/分析,周末记录和分享一下:
一、几点值得Mark的笔记
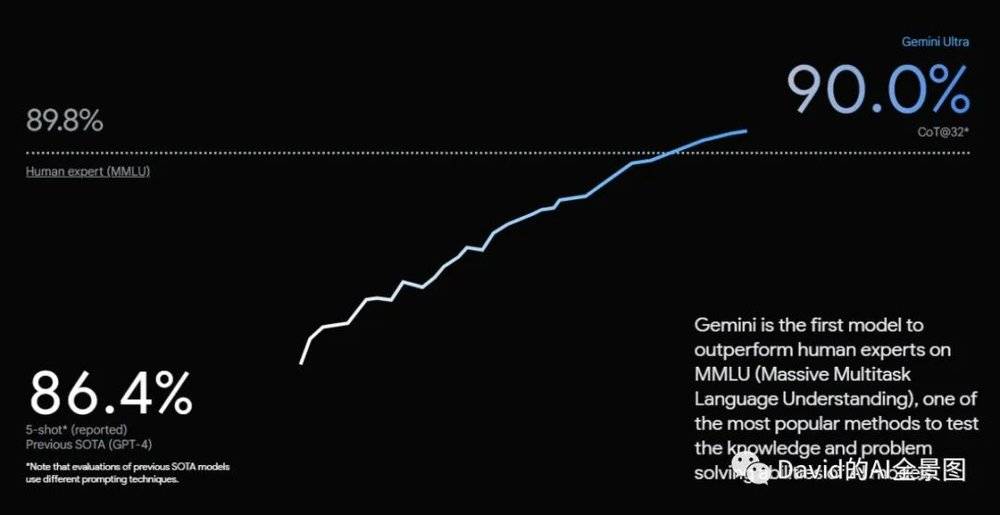
Gemini Ultra的得分为90.0%,是第一个在MMLU(大规模多任务语言理解)上超过人类专家的模型,类似于高考。国内外也有类似的评测基准。
比如C-Eval/CMMLU/GaoKao/LucyEval/SuperClue/OpenCompass/FlagEval等等。
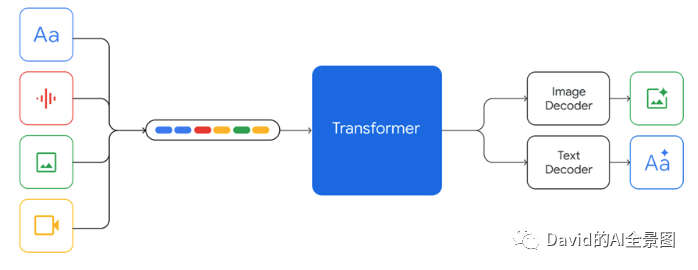
2. 此次Google对Gemini宣传突出的最大亮点——多模态。“Gemini设计成原生的多模态,从一开始就在不同的模态上进行预训练。助于Gemini从头开始无缝地理解和推理各种输入,远远优于现有的多模态模型——其能力在几乎每个领域都是最先进的。”

遵循 next token prediction 的方式,Gemini 把多模态数据从头训练,包括文本、图片、音频、视频等,所有模态数据转换为 token,最后变成一维线性输入(不同的模态按照颜色顺序标记),让模型预测 next token。
3. Google一口气发布了三个规格的模型:Ultra是最大的,对标GPT4和4V、还没有开放(12月13日开放API)。Pro对标GPT3.5,在美区Bard上可以用(我试了下我的Bard,还是之前的LaMDA)。Nano是小模型,在谷歌的Pixel 8手机上可以用。

4. 技术报告中,Google强调了算力优势:“我们宣布迄今为止最强大、高效和可扩展的TPU系统——Cloud TPU v5p ,旨在训练尖端的人工智能模型。”
翻译成大白话,就是:微软/OpenAI/Anthropic这些公司,利润(据说70%)都被Nvidia吃了,我的利润还是自己的。(其实微软和OpenAI也在尝试自己做芯片,只是进度慢于Google。)
5. Gemini语音识别在主要语种上有大幅提升(Bleu值比OpenAI的Wisper 2高10个点,但在其他语种上Wisper更强。机器翻译能力在WMT2023的测试集上评测的结果,也比GPT4略高)。
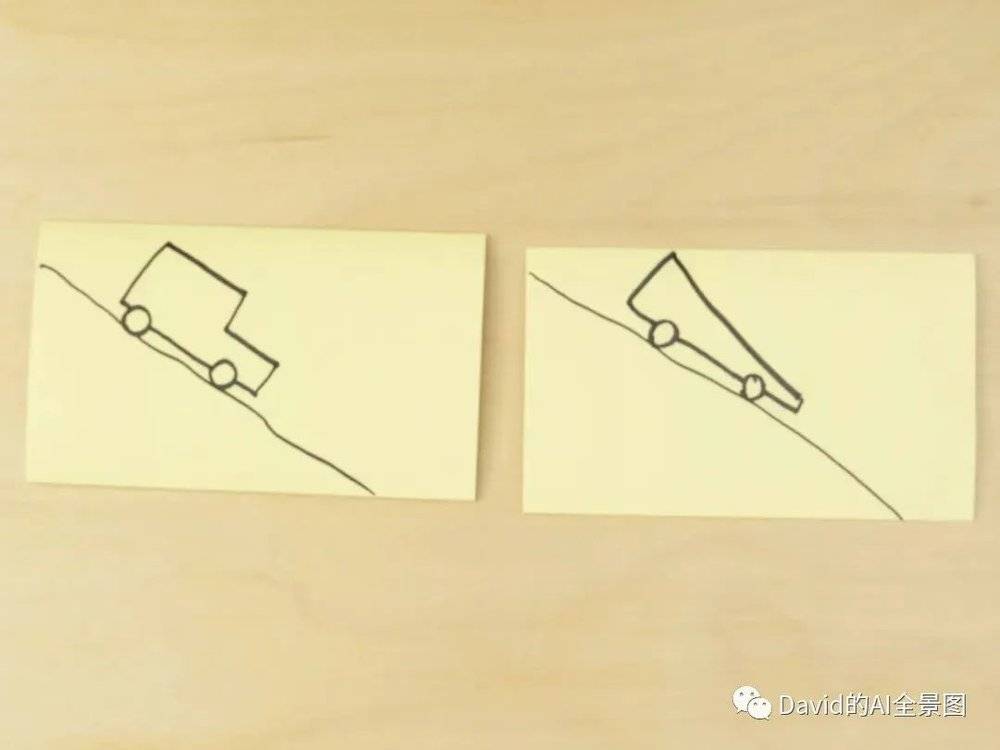
二、一个简单的评测
没用视频,用这张图试了下一些有多模态能力的模型。方法是:上传这张图,然后问:从设计上看,图中哪个车会跑得更快?
百度文心4.0:

智谱清言:
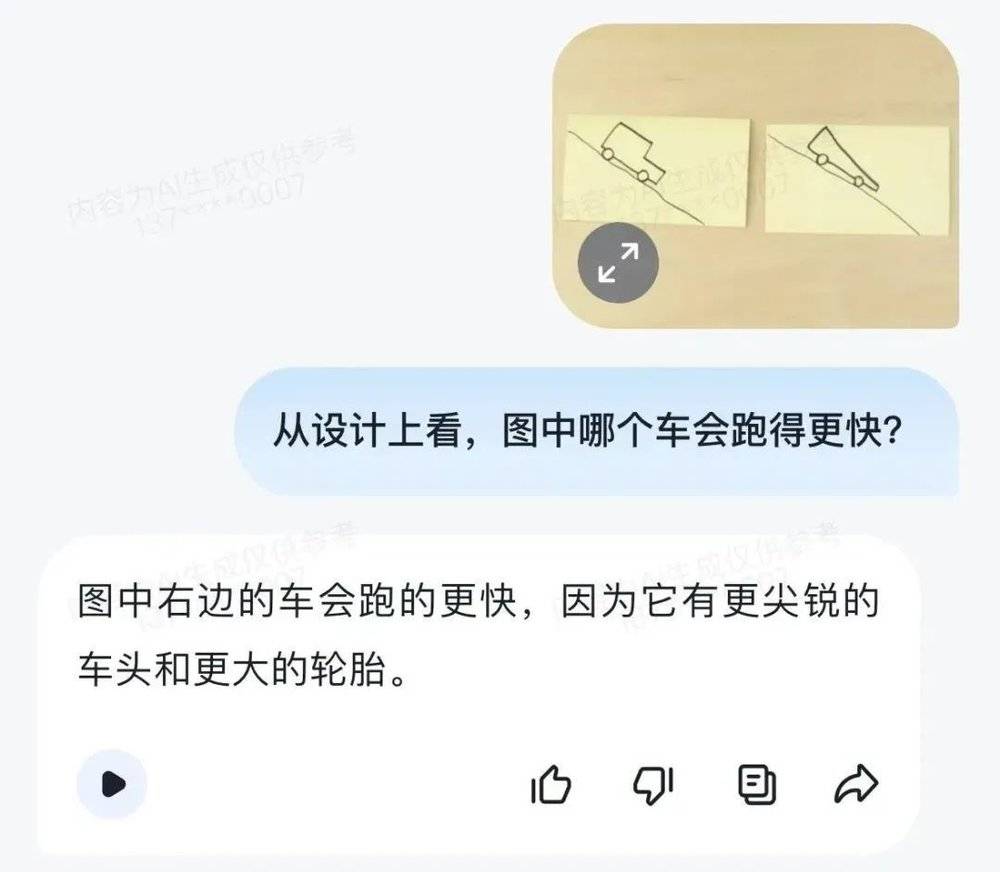
ChatGPT的GPT4:

Google Bard(还不是Gemini Pro):
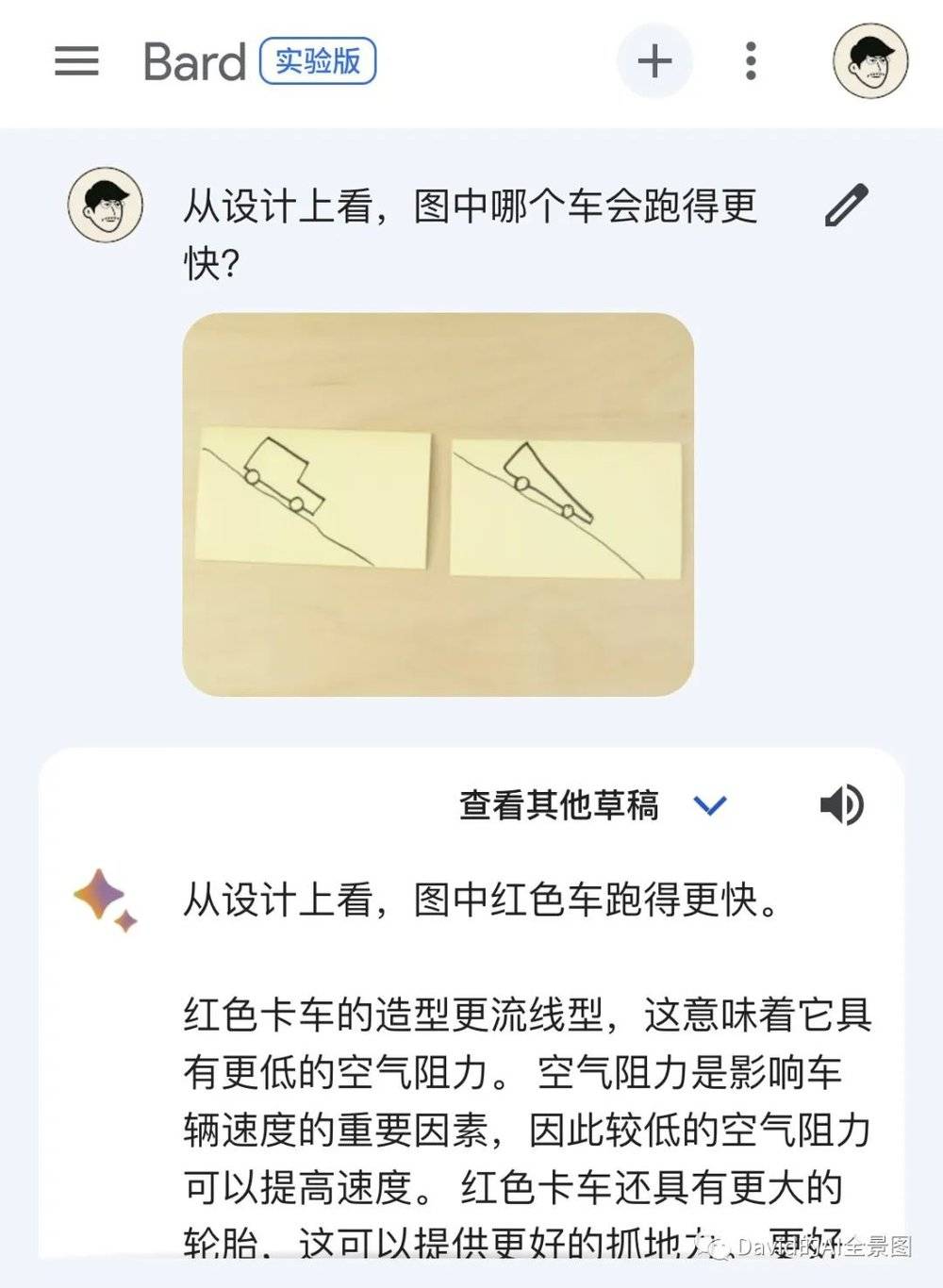
不多评论,不过四个同学都挺有意思~
三、几点想法
1. 关于多模态:实时处理声音、视频流、真实世界交互,意味着具身智能的一大步。可以实时接收信息并实时处理任务,更像人类的生活场景了。Google坐拥全球最大的视频网站Youtube,训练多模态模型条件优越。而且最近大火的文生图Midjourney和文生视频Runway/Pika,证明了多模态在商业上的潜力。
不过,从智能的角度说,多模态被神化了。相比于文本语言模型,多模态模型从智能上来说提升并不大,模型在理解、推理、创造方面并没有显著的提升。除了视频的训练难度,我猜想,我们低估了文本。Rust创始人Graydon Hoare说过:“所有的文学和诗歌、历史和哲学、数学、逻辑、编程和工程都依靠文本编码来表达它们的想法,这不是一个巧合”。
文本确实保存了人类智慧的精华,古今中外的智慧、对世界万物的认知和发现,自有人类文字记载以来,几乎都存到文本中。
一方面,GPT只是一个读了万卷书的“书呆子”,却已经能具备强大的常识、理解、推理和创造力,颇有点“不出户,知天下;不窥牖,见天道“的味道。另一方面,大自然这本书,到底怎么读?这似乎是一个巨大的问题。从真实世界学习知识,就像行万里路相比于读万卷书,低效太多。
2. Gemini没有现场演示,网传一些复现视频和Demo视频不符,有夸大宣传嫌疑。不过,从Bard不断缩小和ChatGPT差距的事实,以及Google综合能力判断,Gemini Ultra能力不会和宣传的出入太大。
Gemini这一仗奠定了AI领域的双子星格局,我们都低估了Google的隐忍。
从竞争格局看,无论是Meta的开源Llama2,还是主打安全的Anthropic、马斯克的X.ai,目前的差距都拉大了。
3. Google的优势有这些:
组织方面,今年年初DeepMind和Google Brain的合并,解决了力量分散和认知不统一的问题,化劣势为优势。
人才方面,领军人物是AlphaGo的推动者,对AGI理解深刻的Demi Hassabis,首席科学家是工程师传说级人物Jeff Dean。人数方面,技术报告作者栏的人数好几页,已将近千人。已经比OpenAI的人数多(七百多人)。
算力/算法/工程方面:算力上谷歌不像微软和OpenAI高度依赖英伟达,有Cloud TPU v5p。算法上,谷歌是Transformer的发明者,是一直以来算法的领头羊;还有搜索业务本身积累的底层算法和工程能力。
生态方面,Google C端强于微软,微软除了云主要是window/office,而Google拥有几乎微软+苹果的C端能力。另外,模型层和应用层都在一个体系下,动作应该比OpenAI和微软的联盟快。
4. 当然,OpenAI的优势至少也还有这些:
GPT4是3月就发布的,时间上领先了Gemini Ultra 9个月,过几个月是否会发布GPT5?
ChatGPT的是一个Killer app,紧随其后的GPT4发布,OpenAI占领了用户心智,GPT也几乎成了大模型的代名词。
全球一亿多用户形成的用户反馈和数据飞轮,大规模的落地已经铺开。
微软快得不像大公司的Copilot和Azure云渗透,OpenAI的创业心态,关于GPTs和GPT store的生态野望,都是厚实的肌肉。
5. 被神话的多模态前景,被低估的Google的隐忍,被加速的AI进程,被喧嚣淹没的AI风险提醒。
这可能是我们——依然处于早期矇昧的人类,在取得亘古未有的生产力跃迁前的徘徊,也有可能是文明充分发育后,在被硅基超越的悬崖边缘的试探。
不管怎么样,这注定是一段风起云涌,激荡数年,值得观察和记录的人类历史。
本文来自微信公众号:David的AI全景图(ID:aifromchina),作者:李光华DavidLee