译者 | 朱先忠
审校 | 孙淑娟
简介
为什么选择音频数据?
与用于文本和计算机视觉任务的NLP相比,用于音频数据的NLP目前尚没有得到业界足够的重视。因此,现在是时候进行一些改变了!
任务
情绪识别——识别语音中是否表现出愤怒、幸福、悲伤、厌恶、惊讶或中性情绪。 注意:如果你能够完整地阅读完本教程,那么,你应该能够重用本文示例工程中提供的代码来实现任何音频分类任务。
数据集
在本教程中,我们将使用Kaggle上公开可用的Crema-D数据集(在此非常感谢David Cooper Cheyney整理了这个令人敬畏的数据集)。然后点击链接处的下载(Download)按钮。您应该会看到包含Crema-D音频文件的文件archive.zip开始下载了,其中包含了7k+.wav格式的音频文件。
注意:您可以自由使用您自己收集的任何音频数据来取代CremaD数据集。
如果您想继续学习本教程,GitHub示例工程所在地址是https://github.com/V-Sher/Audio-Classification-HF/tree/main/src。
Hugging Face库与训练API
正如本文标题中提到的,我们将使用Hugging Face库来训练模型。特别是,我们将使用这个库中提供的Trainer类API。
那么,为什么使用这里的Trainer类呢?为什么不在PyTorch中编写一个标准的训练循环呢?
以下给出Pytorch框架中的标准样板代码,供您参考:
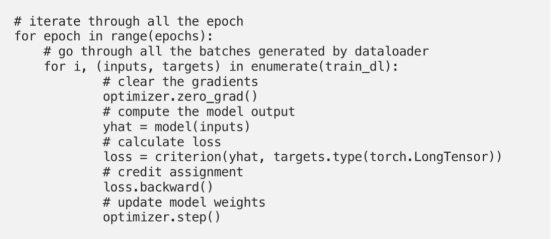
摘自我自己撰写的PyTorch入门教程
相比之下,使用Trainer类能够简化编写训练循环所涉及的复杂性,因此可以通过一行代码来实现训练任务:
trainer.train()
除了支持基本训练循环外,Trainer类还支持在多个GPU/TPU上进行分布式训练,如提前停止这样的回调操作,在测试集上评估结果,等等。所有这些都可以通过在初始化Trainer类时设置几个参数来实现。
如果不是因为什么,我觉得用Trainer类代替普通的PyTorch编码肯定会有助于您开发出一个更有组织性和更干净的代码库。
开发示例工程
安装
虽然是可选的一步,但我强烈建议您通过创建并激活一个新的虚拟环境来开始本教程:在这个虚拟环境中,我们可以完成所有的pip安装。
python -m venv audio_env
source activate audio_env/bin/activate
加载数据集
与任何数据建模任务一样,我们首先需要使用数据集库加载数据集(我们将把此数据集传递给Trainer类)。
pip install datasets
假定我们正在使用自定义数据集(与此库附带的预安装数据集相反)的话,我们需要首先编写一个加载脚本(我们不妨称之为crema.py),并以Trainer类可以接受的格式来加载数据集。
在前一篇文章 中,我已经非常详细地介绍了如何创建这个脚本。(我强烈建议您仔细阅读源码工程,以便充分了解下面代码片段中提到的config、cache_dir、data_dir等的用法)。数据集中的每个示例都有两个特征:文件(file)和标签(label)。
dataset_config = {
"LOADING_SCRIPT_FILES": os.path.join(PROJECT_ROOT, "crema.py"),
"CONFIG_NAME": "clean",
"DATA_DIR": os.path.join(PROJECT_ROOT, "data/archive.zip"),
"CACHE_DIR": os.path.join(PROJECT_ROOT, "cache_crema"),
}
ds = load_dataset(
dataset_config["LOADING_SCRIPT_FILES"],
dataset_config["CONFIG_NAME"],
data_dir=dataset_config["DATA_DIR"],
cache_dir=dataset_config["CACHE_DIR"]
)
print(ds)
********* OUTPUT ********DatasetDict({
train: Dataset({
features: ['file', 'label'],
num_rows: 7442
})
})
注意:当我们为CremaD数据集创建一个datasets.Dataset对象时(要传递给Trainer类),不一定非要这样做。我们还可以定义和使用torch.utils.data.Dataset(类似于我们在教程https://towardsdatascience.com/recreating-keras-code-in-pytorch-an-introductory-tutorial-8db11084c60c中创建的CSVDataset)。
编写模型训练脚本
Github仓库中的工程目录结构如下图所示:

下面,让我们开始撰写脚本文件audio_train.py。
导入必需的库
import os
import logging
import librosa
import wandb
import numpy as np
from datasets import DatasetDict, load_dataset, load_metric
from transformers import (
HubertForSequenceClassification,
PretrainedConfig,
Trainer,
TrainingArguments,
Wav2Vec2FeatureExtractor,
)
from utils import collator
logging.basicConfig(
format="%(asctime)s | %(levelname)s: %(message)s", level=logging.INFO
)
实验跟踪(可选)
USER = "vsher"
WANDB_PROJECT = "audio-classifier"
wandb.init(entity=USER, project=WANDB_PROJECT)
这段代码节选自文件wandp.py。
我们在本处代码中使用了Weight&Biases进行实验跟踪。因此,请确保您已经创建了一个相应的账户;然后,根据您个人的详细信息替换上述代码中的USER和WANDB_PROJECT。
加载特征提取器
[问题]从广义上讲,什么是特征提取器?
[回答]特征提取器是一个负责为模型准备输入特征的类。例如:对于图像,可以包括裁剪图像、填充;对于音频,可以包括将原始音频转换为频谱图特征、应用标准化、填充等。
针对图像数据的特征提取程序示例代码如下:
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
“do_normalize”: true,
“do_resize”: true,
“feature_extractor_type”: “ViTFeatureExtractor”,
“image_mean”: [0.5, 0.5, 0.5],
“image_std”: [0.5, 0.5, 0.5],
“resample”: 2,
“size”: 224
}
更具体地说,我们将使用Wav2Vec2FeatureExtractor类。其实这个类是SequenceFeatureExtractor类的一个派生类,它是Huggingface提供的用于语音识别的通用特征提取类。
归纳来看,共有三种方法可以使用Wav2Vec2FeatureExtractor类:
方法1:使用默认值。
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor()
print(feature_extractor)
**** OUTPUT ****
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
方法2:修改任何Wav2Vec2FeatureExtractor参数以创建自定义特征提取程序。
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(
sampling_rate=24000,
truncation=True
)
print(feature_extractor)
**** OUTPUT ****
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 24000,
"truncation": true
}
方法3:因为我们不需要任何定制,所以我们只需使用from_pretrained()方法加载预处理模型的默认特征提取器参数(通常存储在名为preprocessor_config.json的文件中)。由于我们将使用facebook/hubert-base-ls960作为基本模型,因此我们可以获得其特征提取器参数(可在链接https://huggingface.co/facebook/wav2vec2-base-960h/tree/main处的preprocessor_config.json下进行可视化检查)。
from transformers import Wav2Vec2FeatureExtractor
model = "facebook/hubert-base-ls960"
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model)
print(feature_extractor)
*** OUTPUT ***
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0,
"return_attention_mask": false,
"sampling_rate": 16000
}
为了看一下特征提取器的具体使用情形,让我们将一个虚拟音频文件作为raw_speech提供给Wav2Vec2FeatureExtractor:
model_id = "facebook/hubert-base-ls960"
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model_id)
audio_file = "dummy1.wav"
audio_array = librosa.load(audio_file, sr=16000, mono=False)[0]
input = feature_extractor(
raw_speech=audio_array,
sampling_rate=16000,
padding=True,
return_tensors="pt"
)
print(input)
print(input.shape)
print(audio_array.shape)
***** OUTPUT ******
{'input_values': tensor([[-0.0003, -0.0003, -0.0003, ..., 0.0006, -0.0003, -0.0003]])}
torch.Size([1, 36409])
(36409,)
需要注意的几点:
- 特征提取器的输出是一个包含input_values的字典。它的值只不过是应用于audio_array的规范化,即librosa库的输出。事实上,input.input_values和audio_array两者都具有相同的形状。
- 调用特征提取程序时,请确保使用的采样频率sampling_rate与基础模型在训练数据集时所使用的相同。我们正在使用这个Facebook模型进行训练,它的模型卡明确声明以16Khz的频率采样语音输入。
- return_tensor可以分别取值为“pt”、“tf”和“np”(分别对应于PyTorch张量、TensorFlow对象和NumPy数组)。
- 填充对于单个音频文件来说没有多大意义,但当我们进行批处理时,它确实有意义,因为它会填充较短的音频(结合额外的0秒或-1秒),使其与最长的音频具有相同的长度。下面是用不同长度填充音频文件的示例:
audio_file_1 = "dummy1.wav"
audio_file_2 = "dummy2.wav"
audio_array_1 = librosa.load(audio_file_1, sr=16000, mono=False)[0]
audio_array_2 = librosa.load(audio_file_2, sr=16000, mono=False)[0]
input_with_one_audio = feature_extractor(
audio_array_1,
sampling_rate=16000,
padding=True,
return_tensors="pt"
)
input_with_two_audio = feature_extractor(
[audio_array_1, audio_array_2],
sampling_rate=16000,
padding=True,
return_tensors="pt"
)
print(input_with_one_audio.input_values.shape)
print(input_with_two_audios.input_values.shape)
***** OUTPUT ****
torch.Size([1, 36409])
torch.Size([2, 37371])
既然我们知道了特征提取器模型的输出在形状上可能会有所不同(这取决于输入音频),那么,在将一批输入推送到模型进行训练之前,填充为什么很重要就很清楚了。处理批次时,我们可以:(a)将所有音频填充到训练集中最长音频的长度,或者(b)将所有的音频截取到最大长度。(a)的问题是,我们不必要地增加存储这些额外填充值的内存开销;(b)的问题是由于截断可能会导致一些信息丢失。
有一种更好的替代方法——在模型训练期间使用数据收集器应用动态填充。我们很快就会看到这种用法的。
在构建批处理(用于训练)时,数据收集器只能对特定的输入批应用预处理(例如填充)。
加载用于分类的基本模型
如前所述,我们将使用Facebook公司的Hubert模型对音频进行分类。如果您对HuBERT的内部工作机制感到好奇,请查看Jonathan Bgn为HuBERT编写的这篇很棒的入门教程。
HubertModel可以说是一个“裸”模型类,它是唯一的一个由24个转换器编码器层组成的堆栈,并为这24个层中的每个层输出原始隐藏状态(不需要指定任何用于分类的特定的预定义参数)。
bare_model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
last_hidden_state = bare_model(input.input_values).last_hidden_state
print(last_hidden_state.shape)
*** OUTPUT ***
torch.Size([1, 113, 1024]) # the hidden size i.e. 113 can vary depending on audio我们需要在这个裸模型之上指定某种分类相应的头部信息,以便可以获取最后一个隐藏层的输出,并将其输入到一个最终输出6个值(六个情感类中的每一个)的线性层中。这正是HubertForSequenceClassification所做的。它在顶部有一个分类头,用于音频分类等任务。
然而,与上面解释的特征提取器配置类似,如果你从预训练模型中获得HubertForSequenceClassification的默认配置,那么,你会注意到,由于其默认配置的定义方式,它只适用于二进制分类任务。
model_path = ""facebook/hubert-large-ls960-ft""
hubert_model = HubertForSequenceClassification.from_pretrained(model_path)
hubert_model_config = hubert_model.config
print("Num of labels:", hubert_model_config.num_labels)
**** OUTPUT ****
Num of labels: 2
为了实现我们的6类型分类目标,我们需要使用PretrainedConfig来更新传递给Hubert模型的配置(请查看“参数微调”一节的介绍:https://huggingface.co/docs/transformers/v4.21.2/en/main_classes/configuration#transformers.PretrainedConfig.architectures)。
NUM_LABELS = 6
model_id = "facebook/hubert-base-ls960"
config = PretrainedConfig.from_pretrained(model_id, num_labels=NUM_LABELS)
hubert_model = HubertForSequenceClassification.from_pretrained(
model_id,
config=config, # because we need to update num_labels as per our dataset
ignore_mismatched_sizes=True, # to avoid classifier size mismatch from from_pretrained.
)
这里有几点需要注意:
- 在第5行,from_pretrained()函数从facebook/hubert-base-ls960加载模型架构和模型权重(即所有24个转换器层的权重+线性分类器)。
注意:如果只执行hubert_model=HubertForSequenceClassification(),则会随机初始化转换器编码器和分类器权重。
- 将ignore_mismatched_sizes参数设置为True很重要,因为如果没有这项设置,那么由于大小不匹配,您会得到一个错误(请参见下图):作为facebook/hubert-base-ls960的一部分提供的分类器权重具有形状(2,classifier_proj_size),而根据我们新定义的配置,权重应该具有形状(6,classifer_proj_size)。考虑到我们将从头开始重新训练线性分类器层,我们可以选择忽略不匹配的大小。

分类器大小不匹配导致的错误信息
冻结网络层以便于微调
一般经验法则是,如果训练预训练模型的基础数据集与您正在使用的数据集有显著不同,最好在顶部解冻和重新训练几层。
首先,我们正在解冻顶部两个编码器层(最靠近分类头)的权重,同时保持所有其他层的权重冻结。为了冻结/解冻权重,我们设置param.require_grad的值为False/True,其中param表示模型参数。
在模型训练期间,解冻权重意味着这些权重将像往常一样更新,以便能够达到当前任务的最佳值。
#首先冻结所有神经网络层
for param in hubert_model.parameters():
param.requires_grad = False
#冻结两个编码器层
layers_freeze_num = 2
n_layers = (
4 + layers_freeze_num * 16
) # 4是指投影器和分类器的权重和偏差。
for name, param in list(hubert_model.named_parameters())[-n_layers:]:
param.requires_grad = True
注意:虽然在训练过程的一开始就开始解冻许多层看起来很直观,但我并不建议这样做。实际上,我从冻结所有层开始实验,只训练分类器头。因为最后的训练结果很不理想(毫不奇怪);所以,我通过解冻两层来恢复训练。
加载数据集
借助于我们的自定义加载脚本crema.py,我们现在可以使用数据集库中的loaddataset()方法来加载数据集。
dataset_config = {
"LOADING_SCRIPT_FILES": os.path.join(PROJECT_ROOT, "src/data/crema.py"),
"CONFIG_NAME": "clean",
"DATA_FILES": os.path.join(PROJECT_ROOT,"data/archive.zip"),
"CACHE_DIR": os.path.join(PROJECT_ROOT, "cache_crema")
}
ds = load_dataset(
dataset_config["LOADING_SCRIPT_FILES"],
dataset_config["CONFIG_NAME"],
cache_dir=dataset_config["CACHE_DIR"],
data_files=dataset_config["DATA_FILES"]
)接下来,我们使用map()函数将数据集中的所有原始音频(.wav格式)转换为数组。
一般来说,map会将函数重复应用于数据集中的所有行/样本上。
这里,函数(定义为lambda函数)接受单个参数x(对应于数据集中的一行),并使用librosa.load()方法将该行中的音频文件转换为数组。如上所述,确保采样率(sr)合适。
# 将原始音频转换为阵列
ds = ds.map(
lambda x: {
"array": librosa.load(x["file"], sr=16000, mono=False)[0]
},
num_proc=2,
)
注意:如果你在这个阶段进行打印(ds)的话,你会注意到数据集中的三个特征:
print(ds)
***** OUTPUT *****
DatasetDict({
train: Dataset({
features: ['file', 'label', 'array'],
num_rows: 7442
})
})
生成数组后,我们将再次使用map,这一次使用helper函数prepare_dataset()来准备输入。
#将数据集处理为训练模型所需的格式
INPUT_FIELD = "input_values"
LABEL_FIELD = "labels"
def prepare_dataset(batch, feature_extractor):
audio_arr = batch["array"]
input = feature_extractor(
audio_arr, sampling_rate=16000, padding=True, return_tensors="pt"
)
batch[INPUT_FIELD] = input.input_values[0]
batch[LABEL_FIELD] = batch[
"label"
] #colname必须是标签,因为Trainer 类默认会查找它
return batch
在此,prepare_dataset是一个帮助函数,它将处理函数应用于数据集中的每个样本(或一组样本,如批处理)。更具体地说,该函数做两件事:(1)读取batch["array"]中存在的音频数组,并使用上面讨论的feature_extractor从中提取特征,并将其存储为一个名为input_values的新特征(除了文件、标签和数组之外);(2)创建一个称为label的新特征,其值与batch["label"]相同。
[问题]:您可能想知道每个样本都有标签和标签有什么意义,特别是当它们具有相同的值时。
[原因]:默认情况下,Trainer API将查找列名标签,我们正是考虑到此目的才这样做的。如果您希望在这一步甚至可以完全删除其他标签列,那么请在创建加载脚本时将特征命名为“labels”。
如果仔细观察,你会注意到,与之前lambda函数只接受一个输入参数的映射用例不同,prepare_dataset()需要两个参数。
记住:每当我们需要向map内的函数传递多个参数时,我们都必须向map传递fn_kwargs参数。此参数是包含要传递给函数的所有参数的字典。
根据其函数定义,我们需要为prepare_dataset准备两个参数:(a)数据集中的行和(b)特征提取器——因此我们必须使用以下fn_kwargsas:
# 针对所有样本使用特征抽取器来预处理数据
ds = ds.map(
prepare_dataset,
fn_kwargs={"feature_extractor": feature_extractor},
# num_proc=2,
)
logging.info("Finished extracting features from audio arrays.")
接下来,我们将使用class_encode_column()将所有字符串标签转换为id(0,1,2,3,4,5,6)。
# LABEL TO ID
ds = ds.class_encode_column("label")
# 引入了训练-测试-值分割
# 90%用于训练,10%用于测试+验证
train_testvalid = ds["train"].train_test_split(shuffle=True, test_size=0.1)
# 把用于测试+验证的10%进一步对半分割:一半用于测试,一半用于校验
test_valid = train_testvalid['test'].train_test_split(test_size=0.5)
# 如果您想拥有一个DatasetDict的话,请收集所有人的信息
ds = DatasetDict({
'train': train_testvalid['train'],
'test': test_valid['test'],
'val': test_valid['train']})
开始训练
所有的零碎工作都准备好后,我们现在可以开始使用Trainer类进行训练了。
首先,我们需要指定训练参数,这包括总迭代次数、批大小、存储训练模型的目录、实验日志记录等。
trainer_config = {
"OUTPUT_DIR": "results",
"TRAIN_EPOCHS": 3,
"TRAIN_BATCH_SIZE": 8,
"EVAL_BATCH_SIZE": 8,
"GRADIENT_ACCUMULATION_STEPS": 4,
"WARMUP_STEPS": 500,
"DECAY": 0.01,
"LOGGING_STEPS": 10,
"MODEL_DIR": "models/test-hubert-model",
"SAVE_STEPS": 100
}
# 使用Trainer类进行微调
training_args = TrainingArguments(
output_dir=trainer_config["OUTPUT_DIR"], # output directory
gradient_accumulation_steps=trainer_config[
"GRADIENT_ACCUMULATION_STEPS"
], # 在运行优化步骤之前累积梯度
num_train_epochs=trainer_config[
"TRAIN_EPOCHS"
], #总训练迭代次数
per_device_train_batch_size=trainer_config[
"TRAIN_BATCH_SIZE"
], # 训练期间每个设备的批量大小
per_device_eval_batch_size=trainer_config[
"EVAL_BATCH_SIZE"
], #用于评估的批量大小
warmup_steps=trainer_config[
"WARMUP_STEPS"
], # 学习率调度器的预热步骤数
save_steps=trainer_config["SAVE_STEPS"], # 每100步保存检查点
weight_decay=trainer_config["DECAY"], #权重衰减强度
logging_steps=trainer_config["LOGGING_STEPS"],
evaluation_strategy="epoch", # 在每个迭代末尾输出指标值
report_to="wandb", # 启动指向W&B的日志功能
)- 梯度累积步骤在训练期间想存储大批量但内存有限的情况下非常有用。设置gradient_accumulation_steps=4允许我们在每4个步骤后更新权重:在每个步骤中,batch_size=32个样本被处理并累积它们的梯度。只有在累积足够梯度的4个步骤后,才能更新权重。
其次,我们用这些训练参数实例化Trainer类,并指定训练和评估数据集。
#开始训练
trainer = Trainer(
model=hubert_model, # 实例:对应于将训练的转换器模型
args=training_args, # 训练参数,如下所定义的
data_collator=data_collator,
train_dataset=ds["train"], # 训练数据集
eval_dataset=ds["val"], # 评估数据集
compute_metrics=compute_metrics,
)
这里也还有几个需要考虑的事项:
在第5行,我们使用了data_collator。我们在教程开始时简要讨论了这一点,作为动态填充输入音频阵列的一种方法。数据收集器初始化如下:
# 定义数据收集器以便动态填充训练批次
data_collator = DataCollatorCTCWithPadding(
processor=feature_extractor,
padding=True
)
DataCollatorCTCWithPadding是一个根据链接https://huggingface.co/blog/fine-tune-wav2vec2-english处教程改编的数据类。我强烈建议快速阅读一下这个教程中的“设置Trainer”部分,以详细了解这个类内部的实现逻辑。
这个类中的__call__方法负责准备接收到的输入,但没有太多细节。它从数据集中获取一批样本(记住每个样本都有5个特征:file、labels、label、array和input_values),并返回相同的批次,但是使用processor.pad对input_values应用了填充。此外,批次中的标签将转换为Pytorch张量。
from dataclasses import dataclass
from typing import Dict, List, Optional, Union
import torch
from transformers import Wav2Vec2Processor
INPUT_FIELD = "input_values"
LABEL_FIELD = "labels"
@dataclass
class DataCollatorCTCWithPadding:
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(
self, examples: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_features = [
{INPUT_FIELD: example[INPUT_FIELD]} for example in examples
] # 样本基本上对应于row0, row1,等等...
labels = [example[LABEL_FIELD] for example in examples]
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
batch[LABEL_FIELD] = torch.tensor(labels)
return batch
在第8行,我们定义了compute_metrics(),这是一种告诉Trainer在评估期间必须计算哪些指标(准确度、精度、f1、召回率等)的方法。它将评估预测(eval_pred)作为输入,并使用metric.compute(predictions=.., references=...)将实际标签与预测标签进行比较。同样,compute_metrics()的样板代码也是从链接https://huggingface.co/course/chapter3/3?fw=pt处改编而来的。
from datasets import load_metric
def compute_metrics(eval_pred):
# 定义评估指标
compute_accuracy_metric = load_metric("accuracy")
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return compute_accuracy_metric.compute(predictions=predictions, references=labels)
注意:如果您想发挥创意并显示自定义指标的话,那么,你可以自行修改一下compute_metrics()。在执行此操作之前,您需要知道的只是eval_pred返回的内容。在实际训练模型之前,通过对eval/test数据集运行trainer.predict可以提前发现这一点。在我们的例子中,它返回实际的标签和预测(即logits,在其上应用argmax函数以获取预测的类型):
trainer = Trainer(model=..., args=...,...)
output = trainer.predict(ds["test"])
print(output)
**** 输出*****
PredictionOutput(
predictions=array([
[ 0.0331, -0.0193, -0.98767, 0.0229, 0.01693, -0.0745],
[-0.0445, 0.0020, 0.13196, 0.2219, 0.94693, -0.0614],
.
.
.
], dtype=float32),
label_ids=array([0, 5, ......]),
metrics={'test_loss': 1.780486822128296, 'test_accuracy': 0.0, 'test_runtime': 1.6074, 'test_samples_per_second': 1.244, 'test_steps_per_second': 0.622}
)
核心训练代码
如果你仔细分析的话,你会注意到真正的训练代码也就是一行:
trainer.train()
# 从检查点恢复培训
# trainer.train("results/checkpoint-2000")
请注意:源码中第4行包含从检查站继续训练的命令。但首先要搞清楚:什么是检查点呢?
在训练过程中,Trainer将创建模型权重的快照,并将其存储在由TrainingArguments(output_dir="results")所定义的output_dir位置。这些文件夹通常命名为“checkpoint-XXXX”形式,其中包含模型权重、训练参数等信息。
检查点
您可以分别使用save_strategy和save_steps指定创建这些检查点的时间和频率。默认情况下,检查点将在每500个步骤后保存(save_steps=500)。我之所以提到这一点,是因为我不知道这些默认值。在一次训练(持续7小时)中,我看到没有在输出目录中创建任何检查点。下面的数据是我正在使用的配置信息:
- 训练样本数:6697
- epochs:5
- 批大小:32
- 梯度累积步长Step:4
经过数小时的调试后,我发现在我的例子中,总步骤只有260个,而默认保存只发生在第500个步骤之后。通过在TrainingArguments()的实现代码中添加一个设置(save_steps=100)的方法帮助我修复了这个问题。

在上图的底部,你可以找到优化步骤的总步数。
需要提醒的是,如果您想知道如何计算总步骤数(即本例中的260步),那么请注意下面的计算公式:
总训练批次大小=批量(Batch size)梯度累积步长=324=128
总优化步数=(训练样本/总训练批量)*epochs=(6697/128)*5≈ 260。
在测试集上进行预测和记录结果
#测试结果
test_results = trainer.predict(ds["test"])
logging.info("Test Set Result: {}".format(test_results.metrics))
wandb.log({"test_accuracy": test_results.metrics["test_accuracy"]})
trainer.save_model(os.path.join(PROJECT_ROOT, trainer_config["MODEL_DIR"]))
#把训练后的模型数据日志保存到wandb
wandb.save(
os.path.join(PROJECT_ROOT, trainer_config["MODEL_DIR"], "*"),
base_path=os.path.dirname(trainer_config["MODEL_DIR"]),
policy="end",
)
这里有几件事情需要考虑:
- 要将任何其他度量/变量记录到权重和偏差,我们可以调用wandb.log()方法。例如,在第4行中,我们记录下测试集的精度信息。
- 默认情况下,wandb不会记录经过训练的模型,因此它仅在训练结束后才可在本地计算机上使用。为了显式地存储模型信息,我们需要调用wandb.save(设置policy="end"),表示仅在运行结束时同步文件。
结果和反思
使用不同超参数组合的所有不同模型运行的结果都记录在我的权重和偏差仪表盘中。
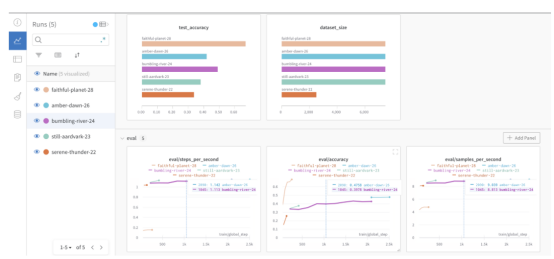
WandB仪表盘
从学习曲线来看,我们最近的运行结果(faithful-planet-28:测试准确率=68%。考虑到只需要4小时的训练,这还算不错)可能会从额外的训练迭代中受益,因为训练和评估损失仍在减少,并且还没有稳定下来(或者更糟的是,开始偏离)。根据是否允许存在这种情况,可能需要解冻更多的编码器层。
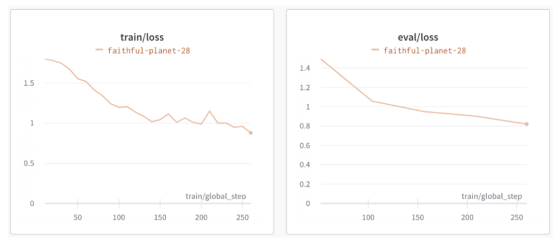
学习曲线展示
这里有几点值得思考:
- 如果我们增加训练迭代次数,那么通过使用回调技巧来提前停止训练可能是值得考虑的方案。
# 提前停止训练
trainer = Trainer(
callbacks=[EarlyStoppingCallback(early_stopping_patience = 10)]
)
- 除了Cuda之外,Trainer最近还添加了对使用新Mac M1 GPU的支持(只需设置args = TrainingArguments(use_mps_device=True))。如果您正在与他们合作,请注意网络上已经有些人提到这种情况下会出现指标下降的问题(这是一个已知的错误,请参阅链https://github.com/huggingface/transformers/issues/17971处提到的问题)。
结论
希望您现在能够更加自信地使用转换器库来微调深度学习模型。如果你真正在推进这个项目,那么,请与我和更广泛的社区共同分享您的成果(以及提高准确性的步骤)。
与任何ML项目一样,关注负责任的AI开发对于评估未来工作的影响至关重要。最近的研究表明,情绪检测方法可能具有内置的性别/种族偏见,并可能对现实世界造成伤害,这一点变得更加重要。此外,如果您正在处理敏感音频数据(例如包含信用卡详细信息的客户支持电话),请应用脱敏技术来保护个人身份信息、敏感个人数据或业务数据。
像往常一样,如果有更简单的方法来实现或解释本文中提到的一些事情,请您告诉我一下。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Fine-Tuning HuBERT for Emotion Recognition in Custom Audio Data Using Huggingface,原文作者:Dr. Varshita Sher