作者 | Roman Kashitsyn
编译 | 言征
Rust是语言设计领域的一个热点。它允许我们用简洁、可移植、有时甚至是漂亮的代码构建高效、内存安全的程序。
然而,凡事都有两面,不会到处都是玫瑰和阳光。内存管理的细节通常会让开发工作陷入抓狂,并使代码比“高级”编程语言(如Haskell或OCaml)中的,更丑陋、更重复。最让人恼怒的是,在几乎所有情况下,这些问题都不是编译器的缺陷,而是Rust团队设计选择的直接后果。
《编程元素》一书中,作者Alexander Stepanov写到:“函数式编程处理值;命令式编程处理对象。”本文通过丰富的案例详细介绍了如果你以函数式编程思维来处理Rust,它会有多令开发者沮丧,以及Rust也别无选择的原因。建议收藏。
一、对象和引用:万恶之源
值和对象起着互补的作用。值是不变的,并且与计算机中的任何特定实现无关。对象是可变的,并且具有特定于计算机的实现。
——Alexander Stepanov,"Elements of Programming"
在深入研究Rust之前,了解对象、值和引用之间的差异很有帮助。
在本文的上下文中,值是具有不同身份的实体,例如数字和字符串。对象是计算机内存中值的表示。引用是我们可以用来访问对象或其部分的对象的地址。
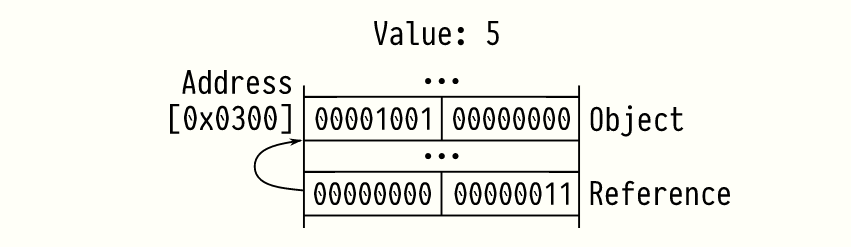
系统编程语言,如C++和Rust,迫使程序员处理对象和引用之间的区别。这种区别使我们能够编写出惊人的快速代码,但代价很高:这是一个永无止境的bug来源。如果程序的其他部分引用对象,那么修改对象的内容几乎总是一个错误。有多种方法可以解决此问题:
- 忽略掉问题,相信程序员的操作。大多数传统的系统编程语言,如C++,都走了这条路。
- 使所有对象不可变。该选项是Haskell和Clojure中纯函数编程技术的基础。
- 完全禁止引用。Val语言探索了这种编程风格。
- 采用防止修改引用对象的类型系统。ATS和Rust等语言选择了这条路。
对象和引用之间的区别也是意外复杂性和选择爆炸的根源。一种具有不可变对象和自动内存管理的语言包容开发者对这种区别的盲区,并将一切视为一个值(至少在纯代码中)。统一的存储模型解放了程序员的思考精力,使其能够编写更具表达力和优雅的代码。
然而,我们在便利性上获得的东西,却在效率上失去了:纯功能程序通常需要更多的内存,可能会变得无响应,并且更难优化,这意味着项目的进度会很赶。
二、内伤1:漏洞百出的抽象
手动内存管理和所有权感知类型系统会干扰我们将代码抽象为更小的部分的能力。
1.公共表达式消除
将公共表达式提取到变量中可能会带来意想不到的挑战。让我们从以下代码片段开始。
let x = f("a very long string".to_string());
let y = g("a very long string".to_string());
// …如上, "a very long string".to_string() ,我们的第一直觉是为表达式指定一个名称并使用两次:
let s = "a very long string".to_string();
let x = f(s);
let y = g(s);
然而,我们的第一个雏形版本不会通过编译,因为String类型没有实现Copy特性。我们必须改用以下表达式:
let s = "a very long string".to_string();
f(s.clone());
g(s);
如果我们关心额外的内存分配,因为复制内存变得显式,我们可以从积极的角度看到额外的冗长。但在实践中,这可能会很烦人,特别是当你在两个月后添加
h(s) 。
let s = "a very long string".to_string();
f(s.clone());
g(s);
// fifty lines of code...
h(s); // ← won’t compile, you need scroll up and update g(s).
2.同态限制
Rust中, let x = y; 并不意味着t x和y是同一个。一个自然中断的例子是,当y是一个重载函数时,这个自然属性就会中断。例如,让我们为重载函数定义一个短名称。
// Do we have to type "MyType::from" every time?
// How about introducing an alias?
let x = MyType::from(b"bytes");
let y = MyType::from("string");
// Nope, Rust won't let us.
let f = MyType::from;
let x = f(b"bytes");
let y = f("string");
// - ^^^^^^^^ expected slice `[u8]`, found `str`
// |
// arguments to this function are incorrect
该代码段未编译,因为编译器将f绑定到MyType::from的特定实例,而不是多态函数。我们必须显式地使f多态。
// Compiles fine, but is longer than the original.
fn f<T: Into<MyType>>(t: T) -> MyType { t.into() }
let x = f(b"bytes");
let y = f("string");
Haskell程序员可能会发现这个问题很熟悉:它看起来可疑地类似于可怕的单态限制!不幸的是,rustc没有NoMonomorphismRestriction字段。
3.函数abstraction
将代码分解为函数可能比预期的要困难,因为编译器无法解释跨函数边界的混叠。假设我们有以下代码。
impl State {
fn tick(&mut self) {
self.state = match self.state {
Ping(s) => { self.x += 1; Pong(s) }
Pong(s) => { self.x += 1; Ping(s) }
}
}
}self.x+=1语句出现多次。为什么不把它抽取成一个方法…
impl State {
fn tick(&mut self) {
self.state = match self.state {
Ping(s) => { self.inc(); Pong(s) } // ← compile error
Pong(s) => { self.inc(); Ping(s) } // ← compile error
}
}
fn inc(&mut self) {
self.x += 1;
}
}Rust会对我们咆哮,因为该方法试图以独占方式重新借用self.state,而周围的上下文仍然保持对self.state的可变引用。
Rust 2021版实现了不相交捕获,以解决闭包的类似问题。在Rust 2021之前,类似于x.f.m(||x.y)的代码可能无法编译,但可以手动内联m,闭包可以解决该错误。例如,假设我们有一个结构,它拥有一个映射和映射条目的默认值。
struct S { map: HashMap<i64, String>, def: String }
impl S {
fn ensure_has_entry(&mut self, key: i64) {
// Doesn't compile with Rust 2018:
self.map.entry(key).or_insert_with(|| self.def.clone());
// | ------ -------------- ^^ ---- second borrow occurs...
// | | | |
// | | | immutable borrow occurs here
// | | mutable borrow later used by call
// | mutable borrow occurs here
}
}然而,如果我们内联or_insert_with的定义和lambda函数,编译器最终可以看到借用规则成立
struct S { map: HashMap<i64, String>, def: String }
impl S {
fn ensure_has_entry(&mut self, key: i64) {
use std::collections::hash_map::Entry::*;
// This version is more verbose, but it works with Rust 2018.
match self.map.entry(key) {
Occupied(mut e) => e.get_mut(),
Vacant(mut e) => e.insert(self.def.clone()),
};
}
}当有人问你,“Rust闭包可以做哪些命名函数不能做的事情?”你会知道答案:它们只能捕获它们使用的字段。
4.Newtype抽象
Rust中的新类型习惯用法允许程序员为现有类型赋予新的标识。该习语的名称来自Haskell的newtype关键字。
这个习惯用法的一个常见用法是处理孤立规则,并为别名类型定义特征实现。例如,下面的代码定义了一种以十六进制显示字节向量的新类型。
struct Hex(Vec<u8>);
impl std::fmt::Display for Hex {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
self.0.iter().try_for_each(|b| write!(f, "{:02x}", b))
}
}
println!("{}", Hex((0..32).collect()));
// => 000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d1e1f
新的类型习惯用法是有效的:机器内存中十六进制类型的表示与Vec<u8>的表示相同。然而,尽管表示形式相同,编译器并没有将我们的新类型视为Vec<u8>的强别名。例如,如果不重新分配外向量,我们就不能安全地将Vec<Hex>转换为Vec<Vec<u8>>并返回。此外,如果不复制字节,我们无法安全地将&Vec<u8>强制为&Hex。
fn complex_function(bytes: &Vec<u8>) {
// … a lot of code …
println!("{}", &Hex(bytes)); // That does not work.
println!("{}", Hex(bytes.clone())); // That works but is slow.
// … a lot of code …
}总之,newtype习语是一种漏洞百出的抽象,因为它是一种惯例,而不是一种一流的语言特性。
5.视图和捆绑包
每当程序员描述结构字段或向函数传递参数时,她必须决定字段/参数是对象还是引用。或者最好的选择是在运行时决定?这是很多决策!不幸的是,有时没有最佳选择。在这种情况下,我们会咬紧牙关,用稍微不同的字段类型定义同一类型的几个版本。
Rust中的大多数函数通过引用获取参数,并将结果作为自包含的对象返回。这种模式非常常见,因此定义新术语可能会有所帮助。我用生存期参数视图调用输入类型,因为它们最适合检查数据。我称常规输出类型为bundle,因为它们是独立的。
以下代码段来自Lucet WebAssembly运行时。
/// A WebAssembly global along with its export specification.
/// The lifetime parameter exists to support zero-copy deserialization
/// for the `&str` fields at the leaves of the structure.
/// For a variant with owned types at the leaves, see `OwnedGlobalSpec`.
pub struct GlobalSpec<'a> {
global: Global<'a>,
export_names: Vec<&'a str>,
}
…
/// A variant of `GlobalSpec` with owned strings throughout.
/// This type is useful when directly building up a value to be serialized.
pub struct OwnedGlobalSpec {
global: OwnedGlobal,
export_names: Vec<String>,
}
作者复制了GlobalSpec数据结构,以支持两种用例:
GlobalSpec<a>是代码作者从字节缓冲区解析的视图对象。此视图的各个字段指向缓冲区的相关区域。此表示对于需要检查GlobalSpec类型的值而不修改它们的函数很有用。
OwnedGlobalSpec是一个包:它不包含对其他数据结构的引用。此表示对于构造GlobalSpec类型的值并将其传递或放入容器的函数很有用。
在具有自动内存管理的语言中,我们可以在单个类型声明中将GlobalSpec<a>的效率与OwnedGlobalSpec的多功能性结合起来。
三、内伤2:组合便成了“苦修”
在Rust中,从较小的部分组合程序,简直会令人沮丧。
1.对象组合
当开发者有两个不同的对象时,他们通常希望将它们组合成一个结构。听起来很简单?Rust中可不容易。
假设我们有一个对象Db,它有一个方法为您提供另一个对象Snapshot<a>。快照的生存期取决于数据库的生存期。
struct Db { /* … */ }
struct Snapshot<'a> { /* … */ }
impl Db { fn snapshot<'a>(&'a self) -> Snapshot<'a>; }我们可能希望将数据库与其快照捆绑在一起,但Rust不允许。
// There is no way to define the following struct without
// contaminating it with lifetimes.
struct DbSnapshot {
snapshot: Snapshot<'a>, // what should 'a be?
db: Arc<Db>,
}
Rust拥趸者称这种安排为“兄弟指针”。Rust禁止安全代码中的兄弟指针,因为它们破坏了Rust的安全模型。
正如在对象、值和引用部分中所讨论的,修改被引用的对象通常是一个bug。在我们的例子中,快照对象可能取决于db对象的物理位置。如果我们将DbSnapshot作为一个整体移动,则db字段的物理位置将发生变化,从而损坏快照对象中的引用。我们知道移动Arc<Db>不会改变Db对象的位置,但无法将此信息传递给rustc。
DbSnapshot的另一个问题是它的字段销毁顺序很重要。如果Rust允许同级指针,更改字段顺序可能会引入未定义的行为:快照的析构函数可能会尝试访问已破坏的db对象的字段。
2.无法对boxes进行模式匹配
在Rust中,我们无法对Box、Arc、String和Vec等装箱类型进行模式匹配。这种限制通常会破坏交易,因为我们在定义递归数据类型时无法避免装箱。
For example, let us try to match a vector of strings.例如,我们试图对字符串Vector做一个匹配。
let x = vec!["a".to_string(), "b".to_string()];
match x {
// - help: consider slicing here: `x[..]`
["a", "b"] => println!("OK"),
// ^^^^^^^^^^ pattern cannot match with input type `Vec<String>`
_ => (),
}
首先,我们不能匹配一个向量,只能匹配一个切片。幸运的是,编译器建议了一个简单的解决方案:我们必须用匹配表达式中的x[..]替换x。让我们试一试。
let x = vec!["a".to_string(), "b".to_string()];
match x[..] {
// ----- this expression has type `[String]`
["a", "b"] => println!("OK"),
// ^^^ expected struct `String`, found `&str`
_ => (),
}
正如大家所看到的,删除一层框不足以让编译器满意。我们还需要在向量内取消字符串的框,这在不分配新向量的情况下是不可能的:
let x = vec!["a".to_string(), "b".to_string()];
// We have to allocate new storage.
let x_for_match: Vec<_> = x.iter().map(|s| s.as_str()).collect();
match &x_for_match[..] {
["a", "b"] => println!("OK"), // this compiles
_ => (),
}
Forget about balancing Red-Black trees in five lines of code in Rust
Forget about balancing Red-Black trees in five lines of code in Rust.
老实话,放弃在Rust用五行代码搞定平衡红黑树吧!
3.孤立规则
Rust使用孤立(Orphan)规则来决定类型是否可以实现特征。对于非泛型类型,这些规则禁止在定义特征或类型的板条箱之外为类型实现特征。换句话说,定义特征的包必须依赖于定义类型的包,反之亦然。
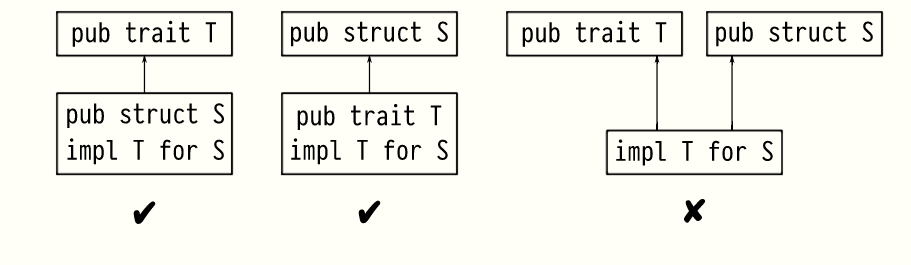
这些规则使编译器很容易保证一致性,这是一种聪明的方式,可以说程序的所有部分都看到特定类型的相同特性实现。作为交换,这一规则使整合无关库中的特征和类型变得非常复杂。
一个例子是我们只想在测试中使用的特性,例如proptest包中的任意特性。如果编译器从我们的包中派生类型的实现,我们可以节省很多类型,但我们希望我们的生产代码独立于proptest包。在完美的设置中,所有的任意实现都将进入一个单独的仅测试包。不幸的是,孤儿规则反对这种安排,迫使我们咬紧牙关,手动编写proptest策略。
在孤立规则下,类型转换特性(如From和Into)也存在问题。我经常看到xxx类型的包开始很小,但最终成为编译链中的瓶颈。将这样的包拆分成更小的部分通常是令人畏惧的,因为复杂的类型转换网络将遥远的类型连接在一起。孤立规则不允许我们在模块边界上切割这些包,并将所有转换移动到一个单独的包中,而不需要做大量乏味的工作。
不要误会:孤立规则是一个默认原则。Haskell允许您定义孤立实例,但程序员不赞成这种做法。让我难过的是无法逃脱孤儿规则。在大型代码库中,将大型包分解为较小的部分并维护浅依赖关系图是获得可接受编译速度的唯一途径。孤立规则通常会妨碍修剪依赖关系图。
四、内伤3Fearless Concurrency是一个谎言
Rust团队创造了术语Fearless Concurrency,以表明Rust可以帮助您避免与并行和并发编程相关的常见陷阱。尽管有这些说法,每次笔者在Rust程序中引入并发时,皮质醇水平都会升高。
1.Deadlocks
因此,对于Safe Rust程序来说,如果同步不正确而导致死锁或做一些无意义的事情,这是完全“好的”。很明显,这样的程序不是很好,但Rust只能握着你的手
——The Rustonomicon,Data Races and Race Conditions
Safe Rust可防止称为数据竞争的特定类型的并发错误。并发Rust程序还有很多其他方式可以不正确地运行。
笔者亲身经历的一类并发错误是死锁。这类错误的典型解释包括两个锁和两个进程试图以相反的顺序获取锁。但是,如果您使用的锁不是可重入的(Rust的锁不是),那么只有一个锁就足以导致死锁。
例如,下面的代码是错误的,因为它两次尝试获取相同的锁。如果do_something和helper_function很大,并且在源文件中相隔很远,或者如果我们在一个罕见的执行路径上调用helper_function,那么可能很难发现这个bug。
impl Service {
pub fn do_something(&self) {
let guard = self.lock.read();
// …
self.helper_function(); // BUG: will panic or deadlock
// …
}
fn helper_function(&self) {
let guard = self.lock.read();
// …
}
}RwLock::read的文档提到,如果当前线程已经持有锁,则函数可能会死机。我得到的只是一个挂起的程序。
一些语言试图在其并发工具包中提供解决此问题的方法。Clang编译器具有线程安全注释,支持一种可以检测竞争条件和死锁的静态分析形式。然而,避免死锁的最佳方法是不使用锁。从根本上解决这个问题的两种技术是软件事务内存(在Haskell、Clojure和Scala中实现)和actor模型(Erlang是第一种完全采用它的语言)。
2.文件系统是共享资源
Rust为我们提供了处理共享内存的强大工具。然而,一旦我们的程序需要与外部世界进行交互(例如,使用网络接口或文件系统),我们就只能靠自己了。
Rust在这方面与大多数现代语言相似。然而,它会给你一种虚假的安全感。
千万要注意,即使在Rust中,路径也是原始指针。大多数文件操作本质上是不安全的,如果不正确同步文件访问,可能会导致数据竞争(广义上)。例如,截至2023年2月,我仍然在rustup(https://rustup.rs/)中遇到了一个长达六年的并发错误(https://github.com/rust-lang/rustup/issues/988)。
3.隐式异步运行时
我不能认真地相信量子理论,因为,物理学应该描写存在于时空之中,而没有“不可思议的超距作用”的实在。
——爱因斯坦
笔者最喜欢Rust的一点是,它专注于本地推理。查看函数的类型签名通常会让自己对函数的功能有一个透彻的理解。
- 由于可变性和生存期注释,状态突变是显式的。
- 由于普遍存在的Result类型,错误处理是明确和直观的。
- 如果正确使用,这些功能通常会导致神秘的编译效果。
然而,Rust中的异步编程是不同的。
Rust支持async/.await语法来定义和组合异步函数,但运行时支持有限。几个库(称为异步运行时)定义了与操作系统交互的异步函数。tokio包是最流行的库。
运行时的一个常见问题是它们依赖于隐式传递参数。例如,tokio运行时允许在程序中的任意点生成并发任务。为了使该函数工作,程序员必须预先构造一个运行时对象。
fn innocently_looking_function() {
tokio::spawn(some_async_func());
// ^
// |
// This code will panic if we remove this line. Spukhafte Fernwirkung!
} // |
// |
fn main() { // v
let _rt = tokio::runtime::Runtime::new().unwrap();
innocently_looking_function();
}这些隐式参数将编译时错误转化为运行时错误。本来应该是编译错误的事情变成了“调试冒险”:
如果运行时是一个显式参数,则除非程序员构造了一个运行时并将其作为参数传递,否则代码不会编译。当运行时是隐式的时,您的代码可能编译得很好,但如果您忘记用神奇的宏注释主函数,则会在运行时崩溃。
混合选择不同运行时的库非常复杂。如果这个问题涉及同一运行时的多个主要版本,那么这个问题就更加令人困惑了。笔者编写异步Rust代码的经验与异步工作组收集的真实情况,可以说是一个悲惨的“事故”!
有些人可能会认为,在整个调用堆栈中使用无处不在的参数是不符合逻辑的。显式传递所有参数是唯一可以很好扩展的方法。
4.函数是有颜色的
2015年,Bob Nystrom在博客《你的函数是什么颜色》中说道:理性的人可能会认为语言讨厌我们。
Rust的 async/.await语法简化了异步算法的封装,但同时也带来了相当多的复杂性问题:将每个函数涂成蓝色(同步)或红色(异步)。有新的规则需要遵循:
同步函数可以调用其他同步函数并获得结果。异步函数可以调用和.await其他异步函数以获得结果。
我们不能直接从sync函数调用和等待异步函数。我们需要一个异步运行时,它将为我们执行一个异步函数。
我们可以从异步函数调用同步函数。但要小心!并非所有同步功能都是相同的蓝色。
没错,有些sync函数非常神奇地变成了紫色:它们可以读取文件、连接线程或在couch上睡眠thread::sleep。我们不想从红色(异步)函数调用这些紫色(阻塞)函数,因为它们会阻塞运行时,并扼杀促使我们陷入异步混乱的性能优势。
不幸的是,紫色函数非常吊轨:如果不检查函数的主体和调用图中所有其他函数的主体,就无法判断函数是否为紫色。这些主体还在进化,所以我们最好关注它们。
真正的乐趣来自于拥有共享所有权的代码库,其中多个团队将同步和异步代码夹在一起。这样的软件包往往是bug筒仓,等待足够的系统负载来显示三明治中的另一个紫色缺陷,使系统无响应。
具有围绕绿色线程构建的运行时的语言,如Haskell和Go,消除了函数颜色的泛滥。在这种语言中,从独立组件构建并发程序更容易、更安全。
五、写在最后
C++之父Bjarne Stroustrup曾说,世界上只有两种语言:一种是人们总是抱怨的,另一种是没人用的。
Rust是一种有“纪律型”的语言,它让许多重要的决策都得到了正确的处理,例如对安全的毫不妥协的关注、特质系统设计、缺乏隐式转换以及错误处理的整体方法。它允许我们相对快速地开发健壮且内存安全的程序,而不会影响执行速度。
然而,笔者经常发现自己被意外的复杂性所淹没,特别是当我不太关心性能,并且想要快速完成一些工作时(例如,在测试代码中)。Rust会将程序解构成更小的部分,并将其由更小的部分来组合程序。此外,Rust仅部分消除了并发问题。
最后,笔者只想说,没有哪种语言是万金油。
原文链接:https://mmapped.blog/posts/15-when-rust-hurts.html#filesystem-shared-resource