本文旨在帮助大家降低在编码过程中写出低性能和耗内存的概率,只要大家在写代码时稍注意下,积少成多。当然,使用代码分析工具也可以调试优化代码的性能,它可以分析出代码中性能和内存消耗的问题,如果这些地方可以重构,那么代码也可以得到改进。但在没有分析工具的情况下,可视化代码检查是必需。
1. 循环
循环的性能是由以下因素决定:
- 循环内进行的工作;
- 在循环中进行的检查,以确定它是否可以退出;
在循环内进行的工作应该保持在最低限度,并且对循环边界进行的检查应该具有最低的开销。典型例子如下:
例子1:在循环开始之前将变量设置为数组的大小,可以节省每次迭代时计算a.size()的开销。
// Lower Performance Version
int a[];
int total = 0;
for(int i = 0; i < a.size(); i++) begin
total += a[i];
end
// Higher Performance Version
int a[];
int a_size;
int total = 0;
a_size = a.size();
for(int i = 0; i < a_size; i++) begin
total += a[i];
end
例子2:在循环中搜索数组的特定值,一旦找到就可以终止循环了。
// Lower Performance Version
int a[50];
int find = -1;
// Look up an index via the array:
foreach(a[i]) begin
if(a[i] == 20) begin
find = i;
end
end
// Higher Performance Version
int a[50];
int find = -1;
// Look up an index via the array:
foreach(a[i]) begin
if(a[i] == 20) begin
find = i;
break;
end
end
例子3:在每次循环迭代时查找关联数组中的值是不必要的,因为它可以在循环开始时查找。另外在小数组方面,foreach()循环结构通常比for(int i = 0;i
// Lower Performance Version
int a[];
int b[string];
foreach ( a[i] ) begin
total += a[i] * b["yes"];
end
// Higher Performance Version
int a[];
int b[string];
int t = b["yes"];
foreach ( a[i] ) begin
total += a[i] * t;
end
2. 决策
在逻辑或算术基础上做决策时,有许多优化可以帮助提高性能。
一旦发现逻辑表达式的一个元素为假,就放弃对它的求值,它可以加快决策的速度,因此逻辑表达式中各个运算数的排序可以避免不必要的性能开销,如下例子:
例子1:对于AND求值,如果表达式的第一项为假,则跳过求值的其余部分。
if(A && B && C) begin
// do something
end
例子2:对于OR求值,如果表达式的第一项为真,则跳过求值的其余部分。
if(A || B || C) begin
// do something
end
例子3:如果表达式中的各项具有不同级别的性能开销,则应该对这些项进行排序,首先计算开销最小的项。
// Lower Performance Version
if((B.size() > 0) && B[$] == 42 && A) begin
// do something
end
// Higher Performance Version
if(A && (B.size() > 0) && B[$] == 42) begin
// do something
end
优化算术运算也可以实现优化,这不仅适用于决策逻辑,也适用于计算变量。如下例子避免了一个乘法操作。
// Lower Performance Version
if(((A*B) - (A*C)) > E) begin
// do something
end
// Higher Performance Version
if((A*(B - C)) > E) begin
// do something
end
如果知道决策树中条件的相对频率,则将最频繁出现的条件移到树的顶部,这最常应用于case语句和嵌套if语句。
例子1:大多数情况下,case语句在一次检查后退出,节省了进一步的比较。
// Lower Performance Version
// Case options follow the natural order:
case(char_state)
START_BIT: // do_something to start tracking the char (once per word)
TRANS_BIT: // do something to follow the char bit value (many times per word)
PARITY_BIT: // Check parity (once per word, optional)
STOP_BIT: // Check stop bit (once per word)
endcase
// Higher Performance Version
// case options follow order of likely occurrence:
case(char_state)
TRANS_BIT: // do something to follow the char bit value (many times per word)
START_BIT: // do_something to start tracking the char (once per word)
STOP_BIT: // Check stop bit (once per word)
PARITY_BIT: // Check parity (once per word, optional)
endcase
例子2:如果ready无效,则不会计算其余代码,然后进行read_cycle检查,这样就不需要进行write_cycle检查了。
// Lower Performance Version
// ready is not valid most of the time
// read cycles predominate
if(write_cycle) begin
if(addr inside {[2000:10000]}) begin
if(ready) begin
// do something
end
end
end
else if(read_cycle) begin
if(ready) begin
// do something
end
end
// Higher Performance Version
// ready is not valid most of the time
// read cycles predominate
if(ready) begin
if(read_cycle) begin
// do something
end
else begin
if(addr inside {[2000:10000]}) begin
// do something
end
end
end
3. 方法调用
task和function统称为method(方法)。在某些情况下,重构调用方法的代码会更好,以便将方法的内容展开直接放到代码中,而不是使用方法调用。如果方法相对较短并且有多个参数,那更可以提升性能了。
在Systemverilog中,通过在task或function调用开始时复制变量,然后将方法执行期间所做的任何更改结果复制回去,来完成向task和function传递参数的功能。如果参数是复杂的变量类型(如字符串或数组),那么这可能会造成相当大的开销,而另一种选择是使用引用(ref)。使用ref节省了参数传递拷贝的开销,如果变量在任务或函数中被更新,则它不会被复制到函数中,因此它也会在调用方法中被更新。如果不想让它被更新,可以让变量为const ref,这将使其称为只读引用的。例子如下,在性能较低的代码版本中,将一个int类型队列和一个字符串复制到函数中。随着队列长度的增长,将会影响到更多的性能和内存。而在高性能版本中,int类型队列和string参数都是引用,这避免了复制操作并加快了函数的执行速度。
// Lower Performance Version
function void do_it(input int q[$], input string name);
// ...
endfunction: do_it
// Higher Performance Version
function void do_it(ref int q[$], ref string name);
// ...
endfunction: do_it
4. 数组
SystemVerilog有许多具有不同特征的数据类型,在使用时需要考虑哪种类型的数组最适合。如下列出了这些数组的特性。
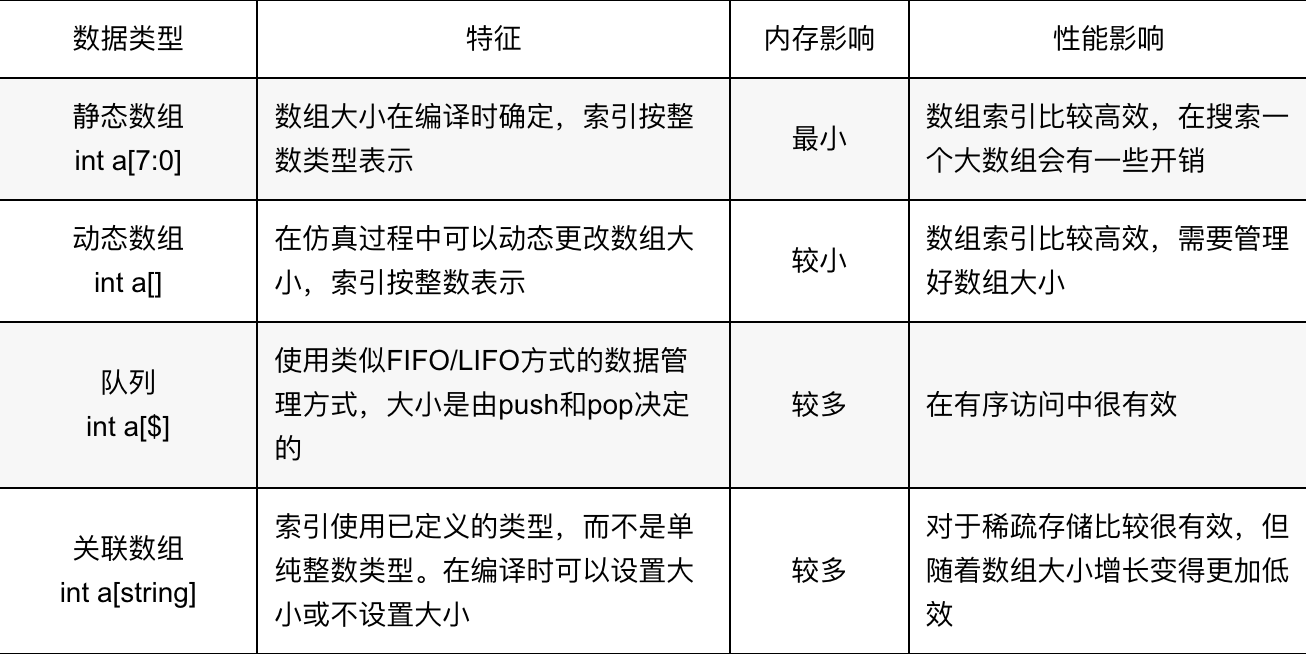
例如,使用关联数组而不是使用静态数组对只有稀疏条目的大型内存空间进行建模可能更有效。但是,如果关联数组由于条目的数量而变得很大,那么使用固定数组来建模内存空间将变得更有效。
在关联数组的使用中,可能会使用未添加到数组的索引进行访问,例如稀疏内存。当关联数组获得超出范围的访问权限时,默认情况下它将返回一条警告消息以及一个未初始化的值。为了避免这种情况,可以查询数组以确定索引是否存在,如果不存在,则不进行访问。如果使用默认变量语法,那么可以通过性能改进来避免这项工作,例子如下:
// Lower Performance Version
// Associative array declaration - no default value:
int aa[int];
if(aa.exists(i)) begin
lookup = aa[i];
end
// Higher Performance Version
// Associative array declaration - setting the default to 0
int aa[int] = {default:0};
lookup = aa[i];
5. 类
在Systemverilog中,类封装了属性(数据变量)和对这些属性进行操作的方法。可以扩展类以添加更多变量,并添加或扩展现有方法以提供新功能。所有这些便利和功能带来了性能开销,可以通过以下方法来优化。
尽量减少创建对象的数量,因为每构造一个对象可能会有一个与之相关的开销。如下优化例子:
// Lower Performance Version
function chi_class get(chi_state_t chi_state);
chi_class chi_txn = new();
if ( chi_state == ON ) begin
// ...
end
return null;
endfunction : get
// Higher Performance Version
function chi_class get(chi_state_t chi_state);
chi_class chi_txn;
if ( chi_state == ON ) begin
chi_txn = new();
// ...
end
return chi_txn;
endfunction : get
直接对变量赋值比调用set()/get()方法更快,调用方法来更新或检查变量比通过类层次路径直接访问带来更高的开销。普通的OOP准则建议类中的数据变量只能通过方法访问。使用直接类层次路径访问变量可以提高性能,但可能会降低代码的可重用性,并且依赖于用户知道所讨论的变量的名称和类型的假设。具体情况需要具体分析。
class name;
int A;
function void set_A(int value);
A = value;
endfunction: set_A
endclass : name
// Lower Performance Version
name m = new();
m.set_A(1);
// Higher Performance Version
name m = new();
m.A = 1;
另外在类中调用方法会带来开销,嵌套或将方法调用链接在一起也会增加开销,在实现或扩展类时,尽量减少所涉及的方法嵌套层次。
6. 随机约束
随机约束生成是SystemVerilog中最强大的功能之一。在类中编写受约束的随机代码时,需要考虑以下几点:
- 除非必须,要尽量减少随机函数的调用;
- 尽量减少rand变量的数量,如果一个值可以从其它随机变量中计算出来,那么它不应该被定义为rand;
- 使用最小的数据类型,比如能用bit就不用logic,并将数据位宽调整到所需要的最小值;
- 使用分层类结构来减少随机化;
- 避免在约束中使用算术运算符;
- 隐含运算符是双向的,使用solve before来强制前项的概率分布;
- 使用pre_randomize()方法预先设置或预先计算随机化过程中使用的状态变量;
- 使用post_randomize()方法来计算依赖于随机变量的变量值;
7. 覆盖率
Covergroup基本上是一组计数器,当采样值与bin匹配时,计数器会增加,覆盖率提升性能的方法是尽可能使用covergroup。Covergroup的基本规则是管理采样bins的创建和covergroup的采样。
每个coverpoint自动转换为一组bins或计数器,用于在覆盖点中采样的变量的每个可能值。这相当于2n个bins,其中n是变量中的位数,但这通常被SystemVerilog auto_bins_max变量限制为最多64个bins。在写covergroup时要仔细分析,在目的达到的基础上,尽量减少创建bins的数目,有助于提供性能。另外,在控制采样时刻上要尽量在期望的行为发生时去调用sample,而不是在每个时钟沿。