根据 IDC 的数据,2022 年,AI 网络市场已达到 20亿美元,其中 InfiniBand 贡献了 75% 的收入。2023 年AI 基础设施建设投资将达到 1540亿美元,到 2026 年将增长到 3000亿美元。展望 2027 年,AI 网络的收入将飙升至超过 100亿美元,其中以太网将超过 60亿美元。以太网和 InfiniBand 都将在此期间强劲增长。与此同时,AI 工作负载的带宽每年增长将超过 100%,远高于数据中心每年 30-40% 的带宽增长。此外,AI 将成为未来十年以太网交换机市场最重要的增长动力。
随着AI 的持续火热,其工作负载也呈指数级增长,网络基础设施正面临极限。AI 基础设施建设需要支持运行在单个计算和存储节点上的大型复杂工作负载,这些节点作为逻辑集群一起工作。AI 网络通过大容量互联结构连接这些大型工作负载。
01
AI 工作负载
AI 工作负载与传统数据中心网络有着根本的不同,虽然超大规模数据中心和 AI /HPC集群之间有很多相似之处,但超大规模数据中心使用的解决方案不足以解决AI /HPC工作负载带来的额外复杂性。AI网络有着以下特征:
并行计算:AI 工作负载是运行相同应用程序、相同计算任务的多台机器之间统一的基础设施;
规模:此类任务的规模可以达到数千个计算引擎(例如GPU、CPU、FPGA 等);
作业类型:不同的任务在大小、运行时间、数据集大小和数量、生成答案的类型、用于编码应用程序的不同语言和运行它的硬件类型等方面有所不同,都会导致为运行AI 工作负载而构建的网络流量模式不断变化;
延迟:延迟是影响作业完成时间(JCT)的重要因素之一。然而,由于此类并行工作负载在多台机器上运行,因此延迟取决于响应最慢的机器;
无损:迟到的响应会延迟整个应用程序。在传统数据中心中,消息丢失将导致重新传输,而在AI 工作负载中,消息丢失意味着整个计算要么错误,要么卡住。正是由于这个原因,AI 网络需要无损行为;
带宽:AI 应用的数据集很大。高带宽流量需要在服务器之间运行,以便应用程序能够获取数据。在现代部署中,AI /HPC计算功能的每个计算引擎的接口速度都达到 400Gbps。
02
AI 集群网络
AI 集群通常有两个不同的网络。第一种网络,也是比较传统的,是所有服务器的外部或面向外部的“前端”网络,当它们面向公共互联网时,需要基于以太网和IP协议。AI 的主要区别在于需要将大量数据输入集群,因此管道比传统的网络服务器大得多。未来的 AI 设计将驱动每台服务器多个 112G SERDES 通道,表现为 100 G 或 400 G 端口。
第二种是“后端”网络,这是一个将AI 集群资源连接在一起的独特网络。对于AI 集群来说,跨计算资源连接到其共享存储和内存,并快速且没有延迟偏差地执行这些任务,对于最大化集群性能至关重要。未来这种新网络的AI 设计将是每个计算服务器有多个 400 G、800 G 或更高端口。
AI 工作负载严重依赖于后端网络。由于一个工作负载在多台服务器上运行,因此需要高带宽、无抖动和无数据包丢失,以确保最高的 GPI 利用率。网络性能的任何下降都会影响JCT。这就需要一个可预测的、无损的后端网络解决方案,这对任何网络技术来说都是一个重大挑战。
随着AI 工作负载的快速增长,AI 集群结构中使用的网络解决方案需要不断发展,以最大限度地利用昂贵的AI 资源。
03
AI网络行业解决方案
如何设计高效的AI 集群组网方案,满足低时延、高吞吐的机间通信,从而降低多机多卡间数据同步的通信耗时,提升 GPU 有效计算时间占比(GPU 计算时间/整体训练时间),对于 AI 网络互联至关重要。下文展示了部分AI高性能网络行业解决方案。
腾讯星脉网络
6月,腾讯云首次完整披露自研星脉高性能计算网络。据称,星脉网络具备3.2T通信带宽,能提升40%的GPU利用率,节省30%~60%的模型训练成本,为AI大模型带来10倍通信性能提升。基于腾讯云新一代算力集群HCC,可支持10万卡的超大计算规模。
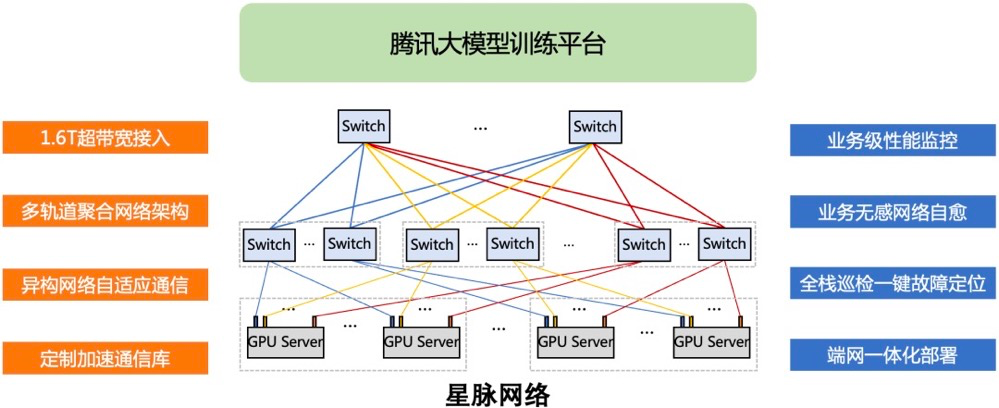
在硬件方面,星脉网络基于腾讯的网络研发平台,采用全自研设备构建互联底座,实现自动化部署和配置。在软件方面,腾讯云自研的TiTa网络协议,采用先进的拥塞控制和管理技术,能够实时监测并调整网络拥塞,满足大量服务器节点之间的通信需求,确保数据交换流畅、延时低,使集群通信效率达90%以上。
华为星河AI网络
华为新一代星河AI网络解决方案,旨在提供一种高效、可靠、安全的数据中心网络解决方案,以支持大规模数据中心的数字化转型。华为星河AI网络解决方案整体技术栈,围绕超高吞吐、长稳可靠和弹性高并发等核心目标来构建关键技术:
超高吞吐:基于华为独创的全局负载均衡NSLB算法、自动化开局和全栈可视运维技术实现算网实时协同调度,将网络有效吞吐从业界的50%提升到98%,大模型训练效率提升20%。
长稳可靠:利用全栈可视运维黑科技,实现大模型训练网络路径、流负载实时可视;结合Packet Event数据面异常感知技术和DPFR故障无感自愈技术,实现亚毫秒级故障快速收敛。
弹性高并发:基于华为独创的多路径智能调度、流感知均衡调优和自适应抗丢包技术,实现 “T级数据小时达”,转发运力提升8倍。
阿里可预期高性能网络
阿里云基础设施事业部推出的可预期网络(Predictable Network)可满足计算任务中的过程数据高效交换需求,是大规模RDMA网络部署实践中不断总结并创新而来的网络技术体系。相比于传统网络的“尽力而为”,可预期网络的概念代表了应用场景对网络服务质量更高的要求,让吞吐率、时延等关键性能指标“可预期”,具备质量保证(QoS)。
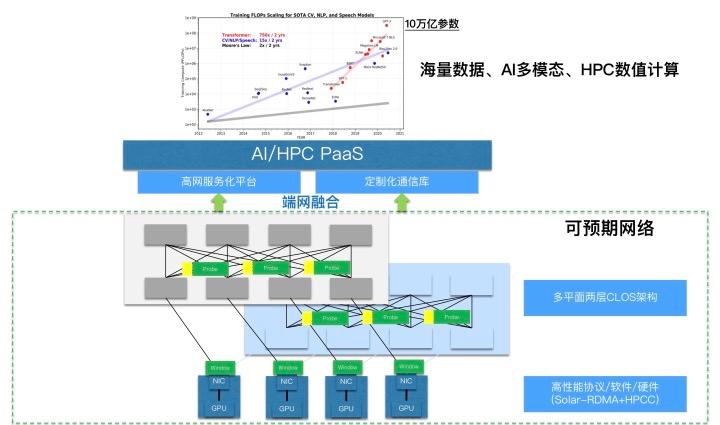
阿里云高性能可预期数据中心网络的核心技术包括:
自研High Performance Network(HPN)高性能网络架构;
基于自研交换机和智能网卡的端网融合核心技术体系;
统一的高性能网络服务平台,Network Unified Service Architecture (NUSA)。
阿里云可预期网络技术体系在架构设计、传输协议、通信库、网络资源调度、网络容器、服务化等维度展开,正在通过智能计算灵骏,为人工智能、大数据分析、高性能计算等高密度计算场景提供服务。
百度AIPod高性能网络
百度认为 AI 高性能网络有三大目标:超大规模、超高带宽以及超长稳定,基于这样的目标,百度有针对性地设计了 AI 大底座里面的 AI 高性能网络—— AIPod。
百度AI 高性能网络 AIPod有约 400 台交换机、3000 张网卡、10000 根线缆和 20000 个光模块。其中仅线缆的总长度就相当于北京到青岛的距离。AIPod 网络采用 3 层无收敛的 CLOS 组网结构。
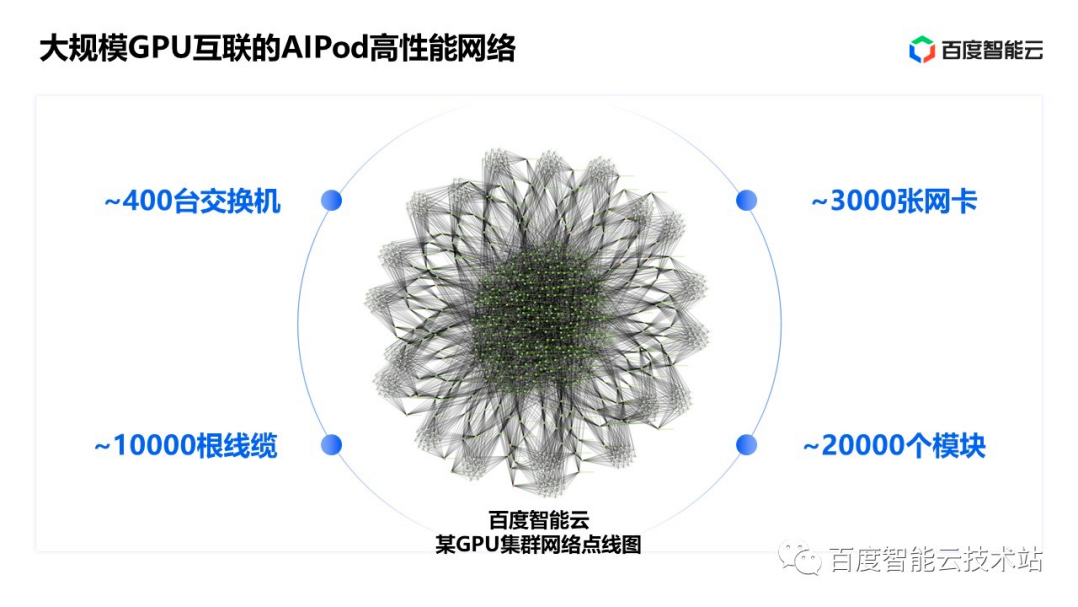
AIPod 高性能网络也是百度智能云 AI 大底座中百度百舸的底层关键技术,决定了大模型训练的能力和效率。大规模、高带宽、长稳定的 AIPod 高性能网络能够帮助用户更高效率、更低成本的训练自己的大模型。
除此之外,像三大运营商、思科、英特尔、博通、谷歌、新华三、中兴、锐捷、青云等公司都有针对AI的不同应用场景推出不同的行业解决方案,感兴趣的朋友可以阅读《盘点:AI 大模型背后不同玩家的网络支撑》。
审核编辑:刘清